Biology often looks like chemistry, but many of its hardest questions are mechanical : how a sheet of cells bends into a tube, how a spheroid opens into a fluid-filled vesicle, or how a growing tumor pushes against the tissue around it. These processes depend not just on genes and signaling, but on force, geometry, material properties, and the way cells physically interact. Cell-based simulations give us a way to study those rules directly, but detailed 3D models have usually forced a tradeoff: simplify the shape, or simulate only a small number of cells.
SimuCell3D is an open-source C++ engine built to push past that limitation. It models each cell as a triangulated mesh and simulates tissue growth and deformation at subcellular resolution, including proliferation, extracellular matrix, fluid cavities, nuclei, and the uneven mechanical properties of polarized epithelia. It can work with spheroids, vesicles, sheets, tubes, and more irregular geometries imported from microscopy images, making it useful for inferring biomechanical parameters from realistic tissue structures.
The ETH Iber lab released v1.0 in 2024. This post is a field report from the fork I’ve been building on top of it. Apart from a few bug fixes in the original code,I focus on a practical performance bottleneck : load imbalance in the simulator’s OpenMP-parallel force and contact loops. I’ll walk through where the imbalance came from, how I measured it, and what it took to make the scheduler adapt so large, high-detail 3D tissue simulations become more tractable.
On the surface, the Static ( = v1.0 ) binary looked like it was using all of the CPU. The
top showed all eight cores pegged - utilization near 800%, the picture of a machine working hard. A tracing profiler told a different story: on the worst steps, close to a third of that “busy” time was threads idling at a barrier while one of them finished an oversized slice.
That gap is invisible to top because it reports aggregate CPU time: 800% across eight cores looks identical whether one thread sprints while seven idle or all eight share the load evenly. It simply can’t see the imbalance. A per-thread view can. If you train models, you already know this failure by a different name: a data-parallel step where one worker drew all the long sequences and the rest sit idle at the all-reduce barrier. Same physics, different address space.
TL;DR. Static OpenMP scheduling handed equal-sized index ranges to every thread regardless of per-cell cost - so whichever thread drew the heavy cells kept them. I built a workload estimator, wired it to per-loop schedule selection, and let it adapt as the tissue grows. Result: ~2.0–2.5× speedups at matched cell counts across the best-supported range (50–250 cells), with consistent wins to ~2.3–2.4× through 1,000 - 10,000 cells on thinner data, and a suggestive ~3× at the largest sizes. SimuCell3D is a C++ 3D tissue-mechanics simulator developed by the Iber lab at ETH Zürich.
The threads were mostly standing around - waiting to pickup computational work
In SimuCell3D the bulk of work is computing forces, contacts, and time steps for cells in a 3D tissue. I held the Static binary under a tracing profiler and measured. During contact detection - the phase that dominates the runtime - a measurable fraction of each parallel region was lost to threads waiting at the barrier while a straggler finished an oversized share. The simulation always completed. The imbalance just silently ate throughput as complexity of the tissue increased.
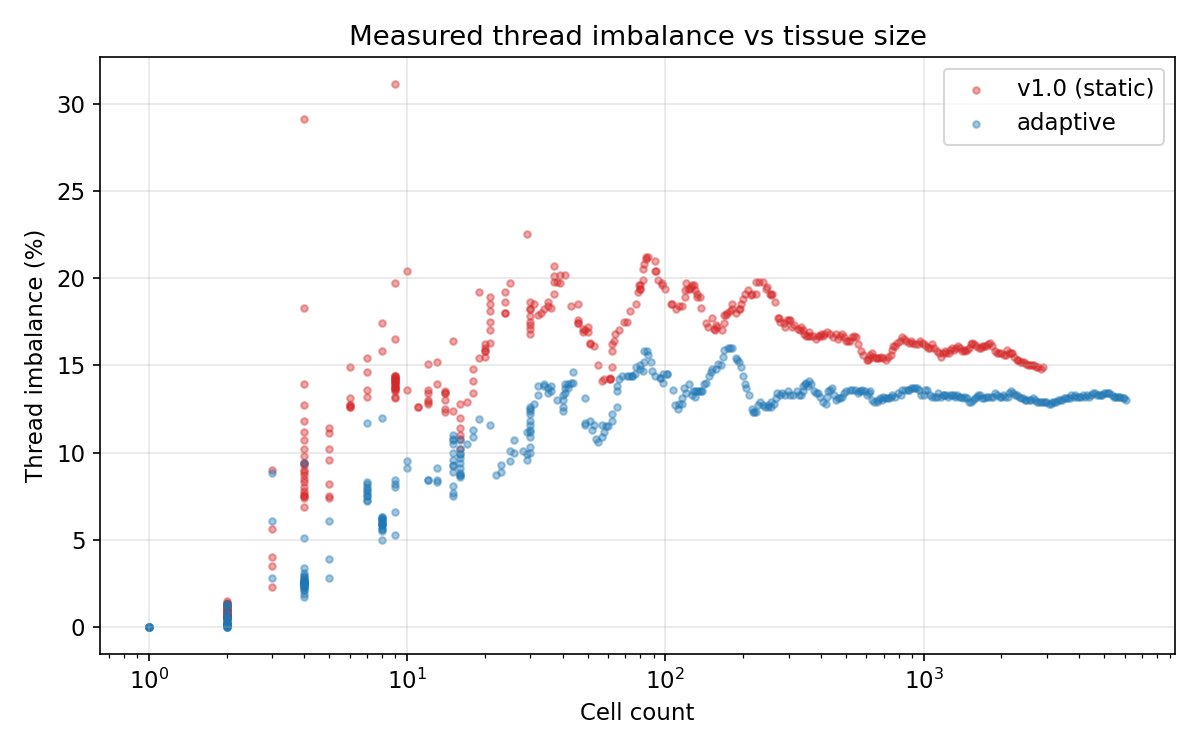 Measured
Measured thread_imbalance_pct across the benchmark run, Static vs Adaptive, plotted against tissue size (log scale). Adaptive sits consistently below Static across the whole range - Static : mean 14.6%, max 31.1%, median 16%; Adaptive : mean 10.7%, max 16%, median 13%. The v1 outliers reaching 31% are the straggler events that static scheduling manufactures by handing all the heavy cells to one thread.
The bottleneck was in the OpenMP directives such that Static mode leans entirely on fixed scheduling: three bare #pragma omp parallel for in solver.cpp with no schedule() clause (on GCC/Clang, the default is static with equal-sized contiguous chunks), an explicit schedule(static) in time_integration.cpp, and another bare parallel loop in the contact model. Static scheduling slices the cells into equal index ranges up front - thread 0 takes cells 0–15, thread 1 takes 16–31, and so on - and never rebalances. For a tissue simulation that assumption fails on the second cell.
The reason is geometric : Each cell is a triangulated mesh, and meshes drift apart in cost. A freshly divided child has fewer faces than its parent; a growing cell has more; a cell wedged in heavy contact spends far longer in its per-face loops than an isolated one. Static scheduling hands out cells by index, not by cost - so whichever thread happened to draw the heavy cells on step one keeps drawing them for the rest of the run.
A single number for “how uneven is it?”
Before changing anything, we need a number to optimize - a fast signal that tells the scheduler “right now the work is lumpy, switch to a finer-grained strategy.”
On this experimental workload, adaptive-mode CoV peaked at 0.16 and never reached the 0.4 or 0.6 chunk-band thresholds built into the scheduler. The chunk divisor stayed at 4 - the coarsest setting - for the entire experiment. The high-CoV dynamic-chunking regime the system is designed for was never exercised on this run. This is modeled as a honest baseline for understanding what the CoV machinery does and why.
Coefficient of variation ( CoV = σ/μ ) measures how spread out a distribution is relative to its mean. When every cell costs the same, CoV is zero and static scheduling is optimal. As some cells grow much heavier than others, CoV climbs and dynamic scheduling starts to win. The catch: we can’t measure CoV by running the loop - that’s the work we’re trying to schedule. We need to estimate each cell’s cost before the loop starts. The estimator in src/solver.cpp is a weighted sum of structural features per cell: a base_cost proportional to face count; a contact_cost scaled by a compile-time constant for the active contact model (0.25 for node–face springs, 0.28 for node–node coupling, 0.32 for face–face coupling, selected by a #if CONTACT_MODEL_INDEX switch so exactly one is live in a given binary); an integration_cost of 0.65 × base_cost for dynamic cells; plus smaller terms for polarization, growth, and mesh quality.
The coefficients were fit by hand against measured per-cell timings and rounded to two decimals. None of this is precise, and it doesn’t need to be at this point. The accurate alternative - profiling every cell’s real cost each step - would cost more than the imbalance it’s trying to remove. A cheap structural proxy wins as long as it stays roughly monotonic with real cost and runs fast. Both hold: the estimator is O(N_cells) and returns a single float.
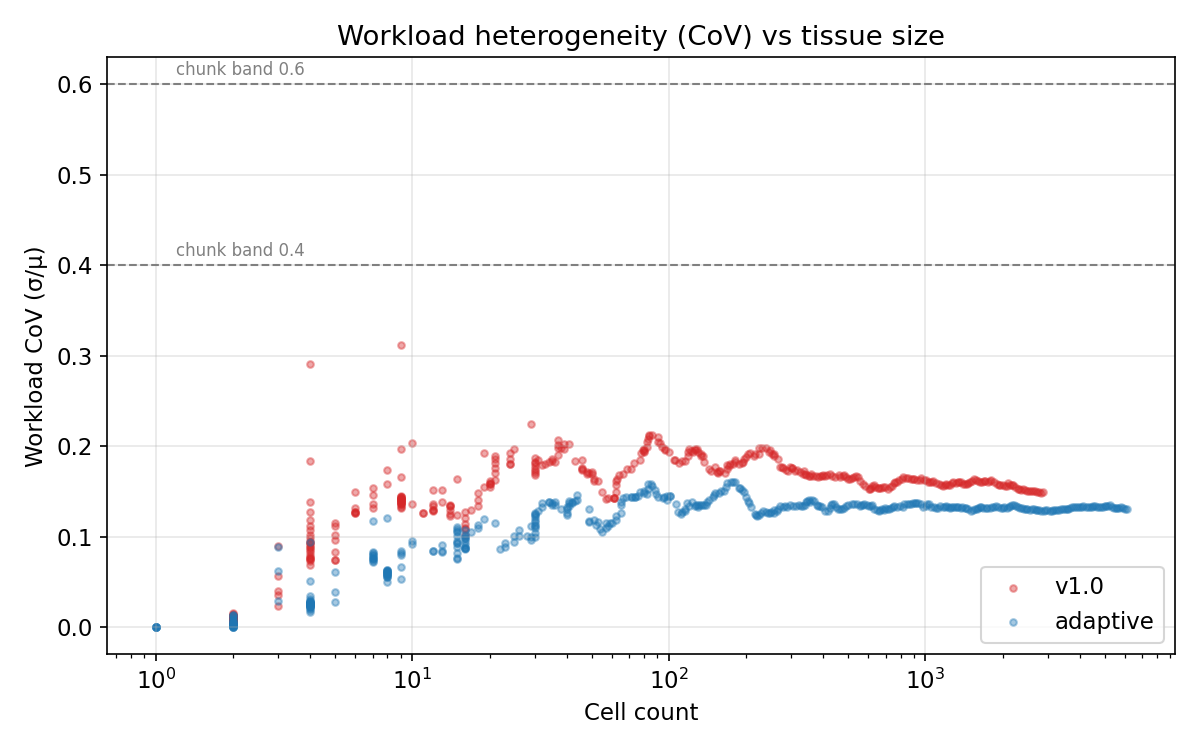 Measured workload CoV vs tissue size across experimental run. Dashed lines mark the 0.4 and 0.6 chunk-size-band thresholds built into
Measured workload CoV vs tissue size across experimental run. Dashed lines mark the 0.4 and 0.6 chunk-size-band thresholds built into calculate_optimal_chunk_size(). Adaptive-mode CoV: mean 0.11, median 0.13, max 0.16. v1 CoV: mean 0.15, median 0.16, max 0.31. Neither mode reached either band. On this workload, the adaptive chunk divisor stayed at 4 (coarsest setting) throughout the entire run.
Three scheduling modes, chosen by how lumpy the work is
static hands each thread a fixed pile up front (fast, but one thread can get stuck with all the slow cells); dynamic gives everyone a shared queue they pull from as they finish (no idle threads, but a small per-grab cost); guided is the middle ground - big grabs first, shrinking toward the tail. If you’ve ever tuned dynamic batching or a work-stealing pool, this is the same trade-off: granularity versus coordination overhead.
The function calculate_optimal_chunk_size() turns the CoV directly into a choice of granularity via a divisor: 4 for CoV ≤ 0.4 (mild imbalance, coarse chunks), 10 for 0.4 < CoV ≤ 0.6 (moderate), 20 for CoV > 0.6 (high imbalance, fine chunks). Then chunk = max(1, min(num_cells / (num_threads × divisor), 100)):
// CoV → chunk granularity (src/solver.cpp, paraphrased)
int divisor = cov <= 0.4 ? 4 // mild imbalance → coarse chunks
: cov <= 0.6 ? 10 // moderate
: 20; // high imbalance → fine chunks
// below 100 cells, always uses divisor=4 (hardcoded fast path)
int chunk = std::max(1, std::min(num_cells / (num_threads * divisor), 100));
The chunk-size formula is only half of mode selection. The actual path the code takes in adaptive mode is a two-component process :
- First,
lookup_benchmark_mode(src/solver.cpp:218–245) consults a 13-entry static table keyed on cell-count range alone - not on thread count or CoV - mapping each range to a fixed schedule mode. The lookup table entries carry hardcoded rationale strings from earlier profiling. - Second,
multi_factor_heuristic(src/solver.cpp:250–314) runs independently, using CoV as its primary input: CoV > 0.6 → dynamic; CoV < 0.15 and tasks_per_thread ≥ 4 → static; 512 ≤ cells ≤ 4096 at moderate CoV → guided.
When the two paths disagree, the benchmark table always wins. The heuristic’s suggestion is logged in verbose output but never applied (src/solver.cpp:725–740). You build a multi-factor heuristic and then hardcode it to lose to a lookup table - the reasoning is that observed speedup data is more trustworthy than a computed estimate. It’s an unusual design choice, and it’s worth knowing.
The less obvious insight is that different loop categories have different workload shapes, so they should not share one schedule. initialize_per_loop_schedules() (src/solver.cpp:884–909) sets four fixed structural assignments:
- Contact detection →
omp_sched_dynamic, chunk = max(1, base_chunk). Most irregular; costs vary with mesh density and contact geometry. - Time integration →
omp_sched_guided, chunk = max(1, base_chunk × 2). More uniform per-cell cost; guided’s shrinking-grab schedule captures most benefit without dynamic’s per-grab overhead. - Mesh updates (face-type classification) →
omp_sched_static, chunk = 0 (equal distribution). The one loop category where cost per cell genuinely is uniform - static maximises cache locality here. - Cell division →
omp_sched_dynamic, chunk = max(1, base_chunk / 2). Rarest and most variable phase; finer-grained dynamic avoids stragglers on the few iterations it fires.
Note: 8 of 10 #pragma omp parallel for loops in src/ carry schedule(runtime), enabling this late-binding approach. Two bare loops without a schedule clause remain in cell_divider.cpp:27 and poisson_sampling.cpp:142; these are not yet wired into the adaptive machinery.
The last piece is adaptation over time. Every 50 iterations (COV_UPDATE_INTERVAL = 50), two functions run back-to-back (src/solver.cpp:1083 and 1086). update_workload_heterogeneity() handles CoV recalculation for non-adaptive modes, gated by a combined condition at line 1153: if CoV has changed by more than 20% and the mode is not adaptive, it then checks whether the implied chunk size would also shift by more than 20% (line 1161) before calling omp_set_schedule(). In adaptive mode that outer gate skips both operations entirely. adaptive_schedule_update() (src/solver.cpp:1211–1296) handles all schedule changes in adaptive mode: it is called every 50 iterations, re-evaluates the simulation phase, and only if the phase has changed does it call omp_set_schedule() and reset recent_division_count_.
A three-phase design, two phases exercised
In 41.3 hours and across all three committed benchmark runs, grep GROWTH across all five performance-diagnostics logs returns zero matches. GROWTH never fired.
The scheduler tracks three simulation phases:
- INITIALIZATION (fewer than 10 cells):
dynamic. Thread count exceeds task count; any fixed assignment starves threads. - GROWTH (division_rate > 0.01, where division_rate = recent_division_count_ / (num_cells × 50)):
dynamicif CoV > 0.4, elseguided. Cell counts and costs are changing fast. - HOMEOSTASIS (all other cases):
staticif cell count > 1,000, elseguided. The tissue has settled; costs are stable enough that static’s cache locality pays off at scale.
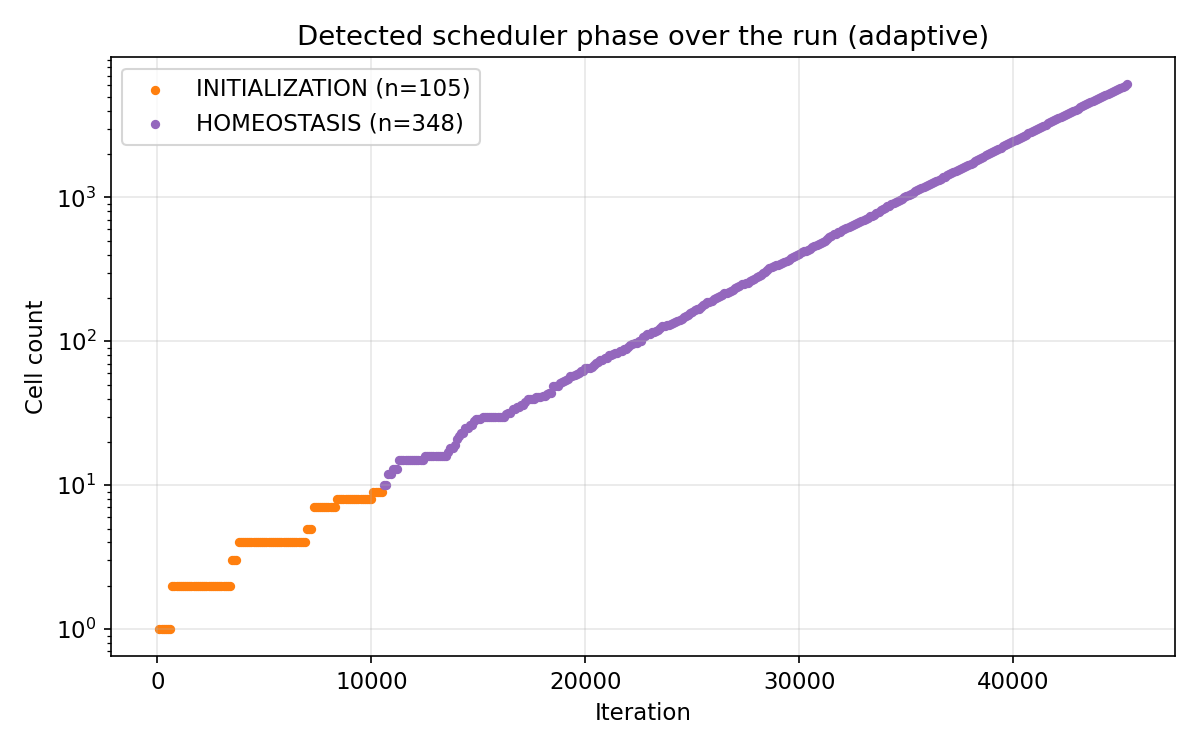 Detected simulation phase across the full 41.3h run (adaptive mode). INITIALIZATION fires for the first ~10,600 iterations while the tissue has fewer than 10 cells. Then the tissue transitions directly to HOMEOSTASIS and stays there for the remainder - growing from 10 to 6,091 cells. GROWTH never fired. Across all three committed benchmark runs,
Detected simulation phase across the full 41.3h run (adaptive mode). INITIALIZATION fires for the first ~10,600 iterations while the tissue has fewer than 10 cells. Then the tissue transitions directly to HOMEOSTASIS and stays there for the remainder - growing from 10 to 6,091 cells. GROWTH never fired. Across all three committed benchmark runs, grep GROWTH across all five performance-diagnostics logs returns zero matches.
This is an honest observation about the workload, not a design flaw. The growth-from-1-cell scenario using parameters_paper_exact.xml divides slowly and steadily enough that recent_division_count_ never exceeded 0.01 × num_cells × 50 - the GROWTH trigger threshold - so the phase stayed in HOMEOSTASIS throughout. A faster-dividing parameter set - or a scenario that starts from a small fixed tissue and forces rapid expansion - would exercise GROWTH. On this workload, the adaptive scheduler spent 105 samples in INITIALIZATION and 348 samples in HOMEOSTASIS, never touching the phase the GROWTH branch was written for.
The numbers
At run’s end adaptive shows 0.030 IPS versus v1’s 0.044 IPS - adaptive looks slower. It’s not: it’s managing 2.66× more cells (6,091 vs 2,288). The right comparison is at matched cell counts.
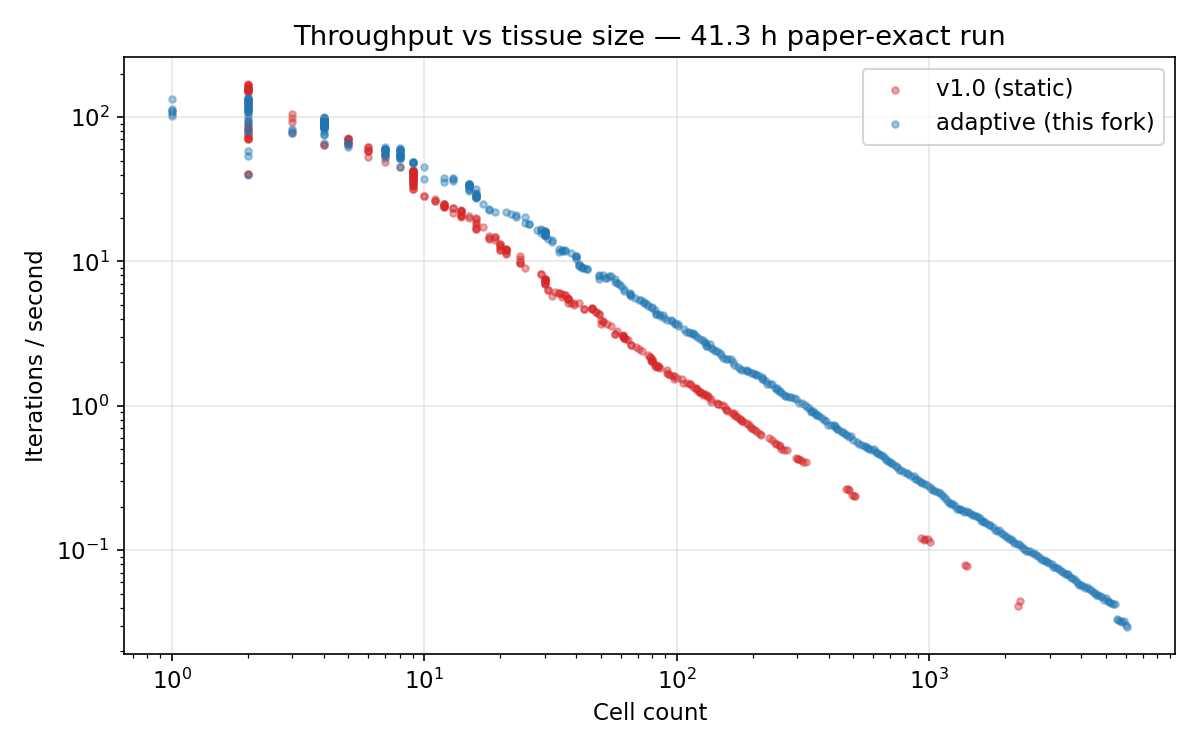 Iterations per second vs cell count (log-log), from the 41.3h benchmark run. Adaptive sits above v1 at every matched cell count. v1 data terminates at ~2,288 cells; adaptive continues to 6,091. The apparent “slower” IPS at run’s end for adaptive is because it’s managing 2.66× more cells - at matched cell counts, adaptive is consistently faster.
Iterations per second vs cell count (log-log), from the 41.3h benchmark run. Adaptive sits above v1 at every matched cell count. v1 data terminates at ~2,288 cells; adaptive continues to 6,091. The apparent “slower” IPS at run’s end for adaptive is because it’s managing 2.66× more cells - at matched cell counts, adaptive is consistently faster.
At matched cell counts the picture is clear: adaptive is faster across the board, and the gap widens as the tissue grows. Speedups:
- 1.43× at 10 cells;
- 2.07× at 50 cells;
- Climbing to ~2.3–2.5× through the 100–500 cell range. The 50–250 cell band is best supported statistically (30, 35, and 22 v1 samples respectively).
- At 500 cells there are only 6 v1 samples; at 1,000 cells there are 5; and the 3.05× at 2,000 cells rests on 2 v1 samples, so treat that as suggestive rather than firm.
Adaptive is solidly ~2.0–2.5× faster across the range where the data is dense, with a plausible upward trend at the largest sizes that needs more data to pin down.
The scaling exponent (time per iteration ~ N^α) tells a related story. Adaptive: α = 1.136 (R² = 0.999). v1: α = 1.213 (R² = 0.998). Lower is closer to linear; adaptive’s ~6% better exponent means the gap widens gradually as the tissue grows, which matches what the throughput curve shows.
The biological signal is essentially a non-event, which is what you want: median pressure deviation between the two modes is 1.71% across 823 matched iterations. The adaptive scheduler changes how threads pick up work - not what the physics computes.
Where the runtime actually goes
To understand why adaptive is faster, it helps to look at where the time goes.
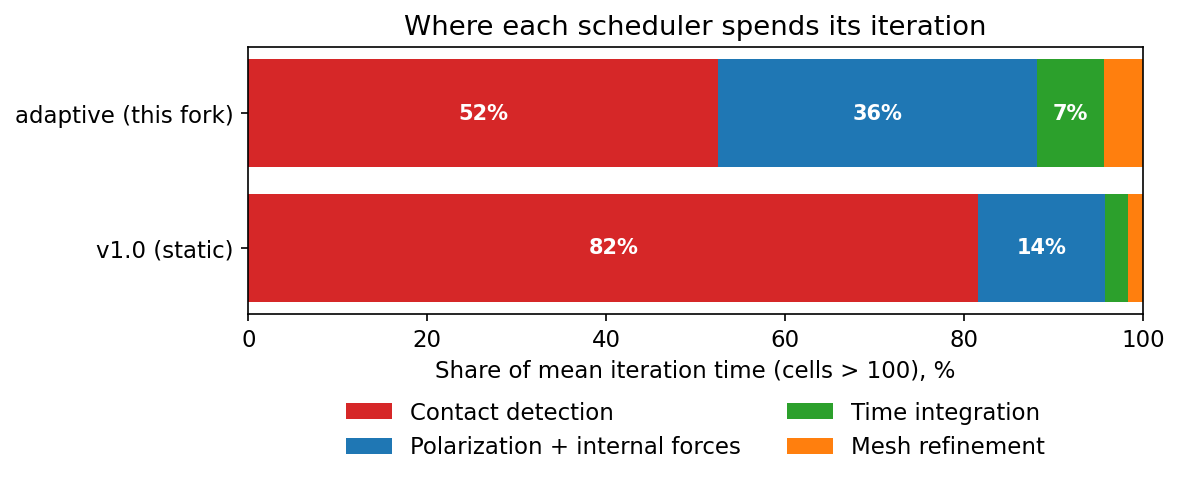 Phase-time fractions (cells > 100) from the 41.3h run. v1: contact detection 81.6%, polarization + internal forces 14.1%, time integration 2.6%, mesh refinement 1.8%. Adaptive: contact detection 52.5%, polarization + internal forces 35.7%, time integration 7.4%, mesh refinement 4.4%. Contact detection drops from 82% to 52% of mean iteration time - by far the biggest shift. The second-largest phase is polarization and internal forces, not time integration.
Phase-time fractions (cells > 100) from the 41.3h run. v1: contact detection 81.6%, polarization + internal forces 14.1%, time integration 2.6%, mesh refinement 1.8%. Adaptive: contact detection 52.5%, polarization + internal forces 35.7%, time integration 7.4%, mesh refinement 4.4%. Contact detection drops from 82% to 52% of mean iteration time - by far the biggest shift. The second-largest phase is polarization and internal forces, not time integration.
Contact detection dominates v1 at 81.6% of iteration time. In adaptive mode it drops to 52.5% - not just because of scheduling, but because the contact detection improvements (USPG rewrite, Morton sorting, SAP switching) run alongside the scheduler. The second-most-expensive phase is polarization and internal forces (14.1% → 35.7%), which becomes more visible in adaptive mode precisely because contact detection has gotten faster. Time integration accounts for only 2.6–7.4% of iteration time - a minor contributor, not a dominant phase.
This is worth stating plainly for causal clarity: the load-imbalance improvement (mean thread_imbalance_pct from 14.6% to 10.7%) is real and consistent across the full run. But the biggest lever in the speedup numbers is the contact-detection work - faster algorithms plus better scheduling of an inherently irregular phase. I don’t have a clean ablation between the USPG/Morton changes and the scheduler; the 41.3h run exercised both together. Turning off Morton sorting and re-running is the measurement this section is missing.
Three changes that compounded the gains
Faster contact detection :
Contact detection is both the most irregular phase and the most expensive, so speeding it up multiplies with the scheduling win. Its spatial-lookup containers (an unbounded uniform grid, “USPG”) switched from std::forward_list to std::vector - better cache behaviour and fewer pointer chases. Morton sorting of faces before USPG insertion was added separately : faces near each other in space land near each other in memory and the cache stops thrashing. Above 500 cells, a different broad-phase algorithm - Sweep-and-Prune - switches on automatically (ADAPTIVE_SAP_CELL_THRESHOLD = 500). SAP projects objects onto axes and finds overlapping intervals; it scales better than a uniform grid at sparse large-N scenes and produces the same exact candidate pairs - it is not a coarser approximation. The contact_detection_algorithm XML parameter accepts uspg, sweep_and_prune, or adaptive; the default is uspg unless explicitly set.
Better CI and memory-safety tooling :
v1.0’s CI ran one Release build and ctest -C Release. The fork adds Debug builds, AddressSanitizer and UndefinedBehaviorSanitizer, and a clang-format check (commit a2ca28e). Latency profiling was added separately in commit b0aac1a (2026-02-15). The sanitizers earned their place immediately: they caught a heap-use-after-free in local_mesh_refiner::split_edge - a reference left dangling after a vector reallocation - that had survived careful manual review (commit d5e2112).
A correctness sweep :
Alongside the performance work: a division-by-zero guard in mat33::inverse, NaN suppression in vec3::angle, a fix for a cell_lst.size() data race in the parallel cell-division loop (cell_divider.cpp), and null checks in parameter_reader. The parallel division bug is the kind that only shows up under the heavier thread utilization the new schedules produce, which is why it mattered to fix it before trusting any benchmark.
What’s still open
A few honest gaps remain:
- Thread Sanitizer isn’t in CI yet. Only ASan and UBSan run. The cell-division parallel section still produces enough benign-looking races that TSan is noisy, and that noise needs triaging before it can gate the build.
- The Python wrapper hasn’t caught up. The new
--schedule=and--diagnostics-csv=CLI flags exist on the C++ binary but aren’t exposed through the pybind11 wrapper -simucell3d_wrapperonly forwards simulation parameters, cell list, thread count, and verbosity. Python users can’t reach the new knobs yet. Tracked for the next release. assert()in hot paths. 306assert()calls still live in productionsrc/(all runtimeassert(), nonestatic_assert). Several have been converted to proper runtime checks in the critical paths; the rest are a slower migration.- The high-CoV machinery is unexercised on committed workloads. The 0.4/0.6 chunk-band thresholds and the GROWTH phase detector are implemented and confirmed in the source, but neither fired on the 41.3h paper-exact run. A faster-dividing scenario would be the right workload to exercise them.
Three things this taught me
One: the most consequential scheduling parameter wasn’t the integrator or time step - it was the order in which threads picked up work. The right choice costs almost nothing at runtime. The wrong choice costs 2×+, silently, because CPU utilization stays pinned at 100% even while thread utilization tanks. top tells you nothing useful here; a tracing profiler tells you everything.
Two: instrumentation before optimization. It would have been easy to flip schedule(static) to schedule(dynamic) and call it done. Building the full measurement stack took longer - but it produced the uncomfortable observation that CoV never triggered the fancy band machinery on this workload, that GROWTH never fired, that the high-CoV branches are correct but untested on these parameters. Knowing those gaps is more useful than assuming everything worked.
Three: fix correctness before you trust a benchmark. The sanitizers found a memory bug that survived manual review; the parallel-division race only surfaces under the heavier thread utilization the new schedules cause. In the right order, you catch those before they quietly contaminate your numbers.
- Code: github.com/nilesh-patil/simucell3d (tag
v2.0, branchmain) - Reference: Runser et al., SimuCell3D, Nature Computational Science (2024)
- Project page: SimuCell3D on Side Projects