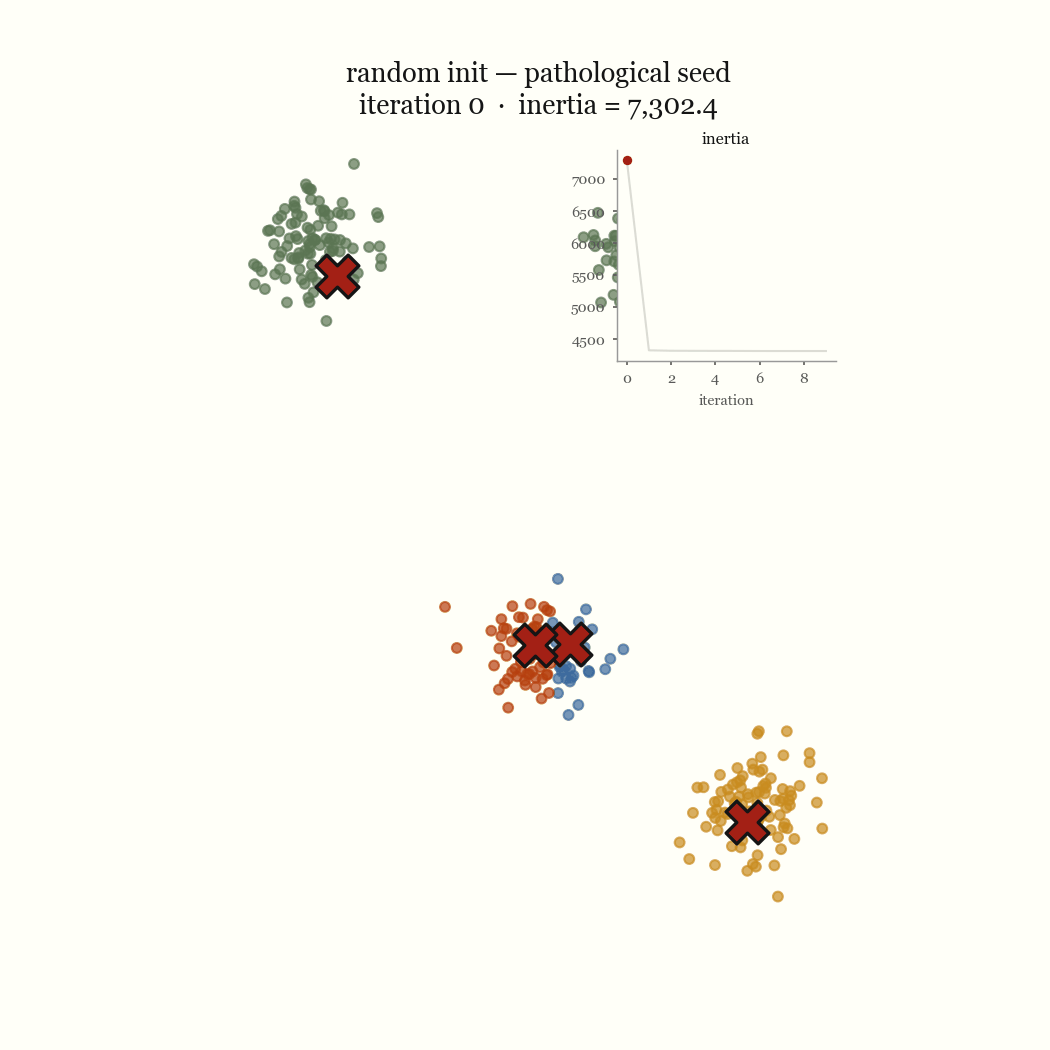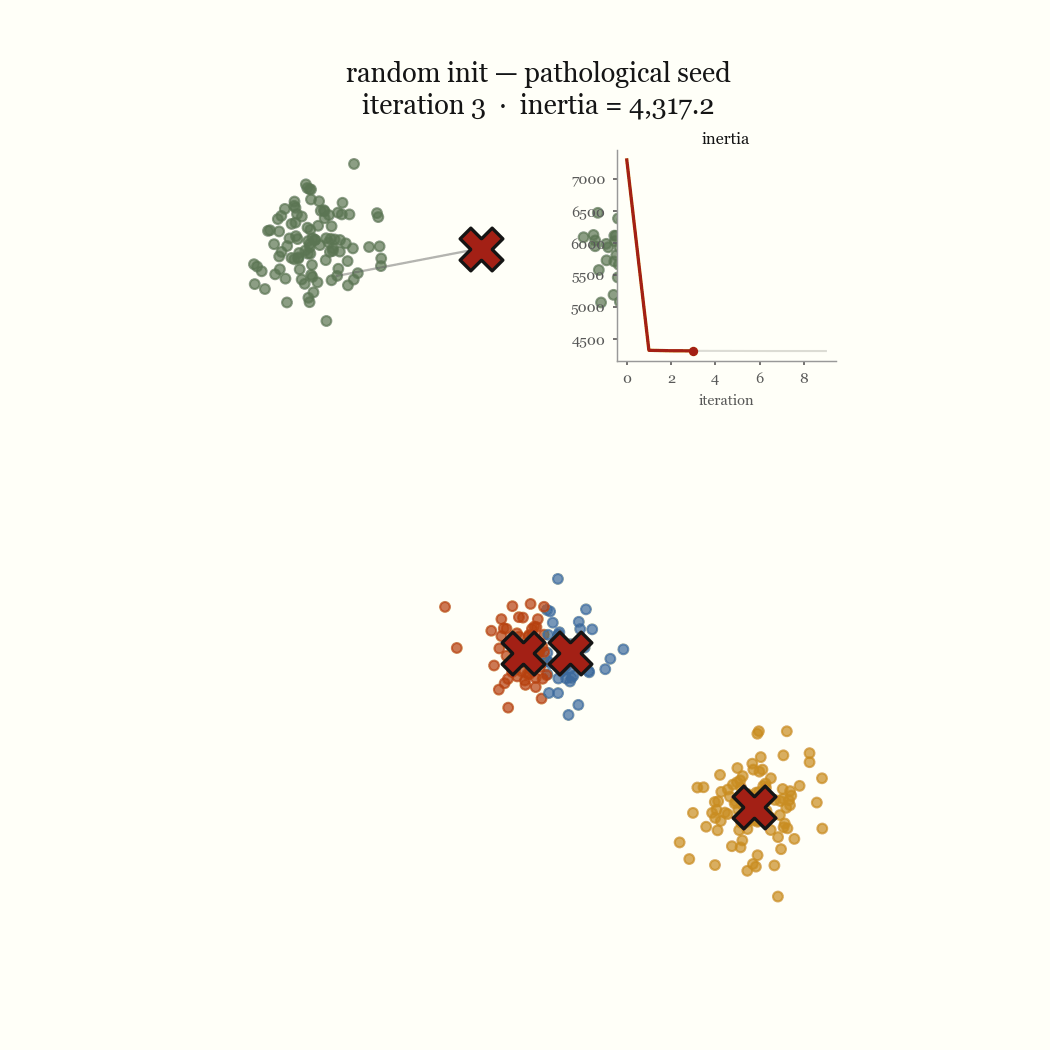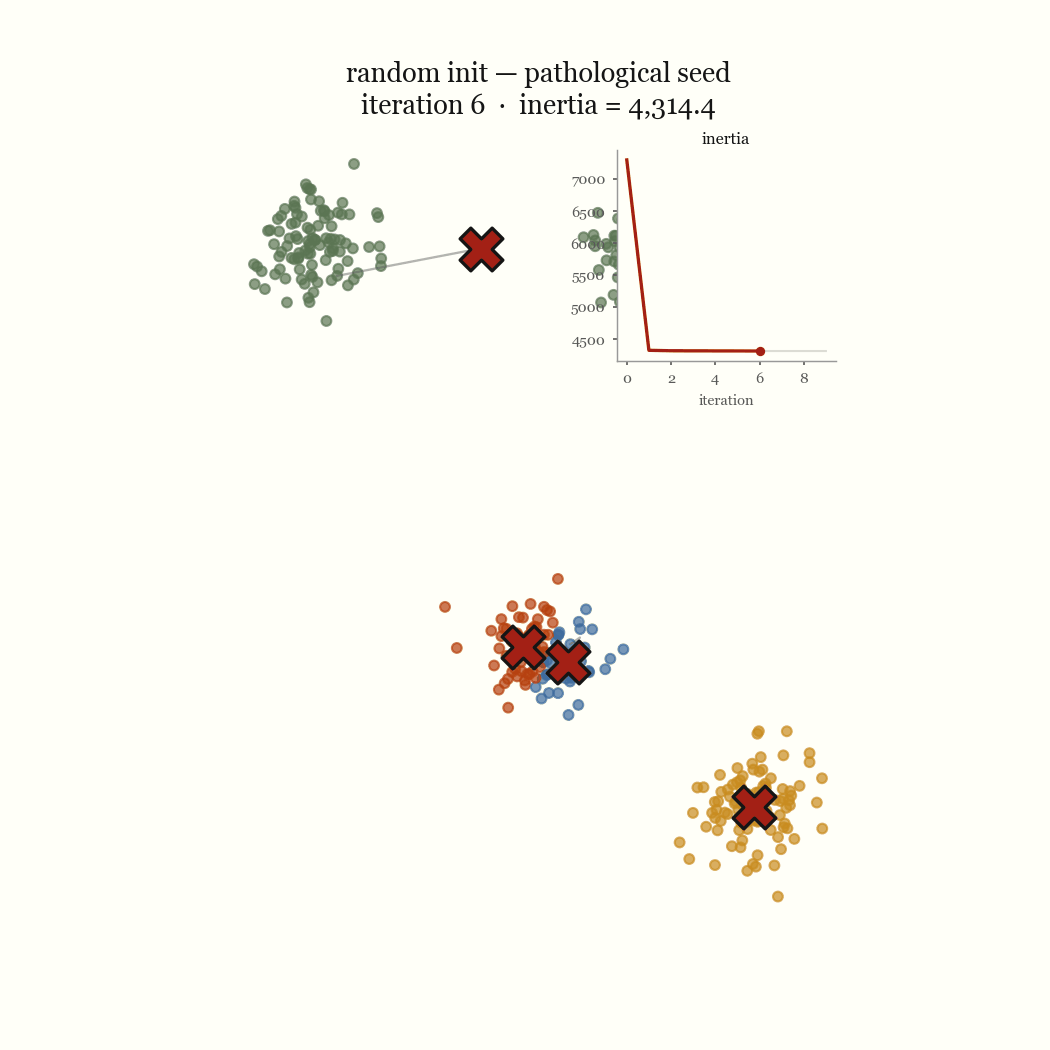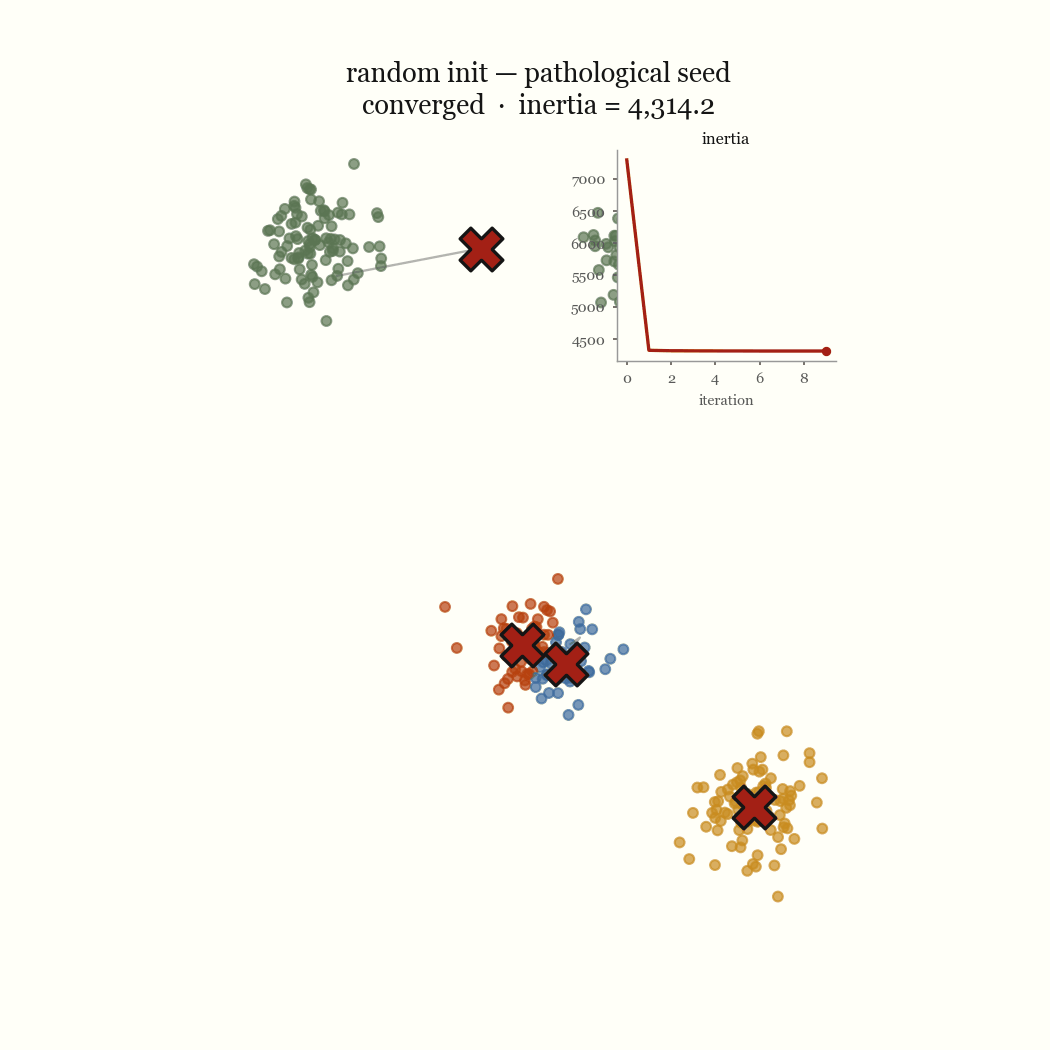
K-Means is Lloyd’s algorithm, and Lloyd’s algorithm is alternating minimization of one objective: the within-cluster sum of squares. Every step it takes drives that objective down, which is why it always converges. When it converges to nonsense, the culprit is the objective’s own assumption that clusters are compact and roughly spherical, not the speed of the descent. The whole story is in where you start.
What K-Means optimizes is easy to write down and easy to forget. Given \(n\) points \(x_1, \dots, x_n\) in \(\mathbb{R}^d\) and a target of \(k\) clusters, we want an assignment of points to clusters \(C_1, \dots, C_k\) and a set of centroids \(\mu_1, \dots, \mu_k\) that together minimize the squared distance from each point to its cluster’s centroid:
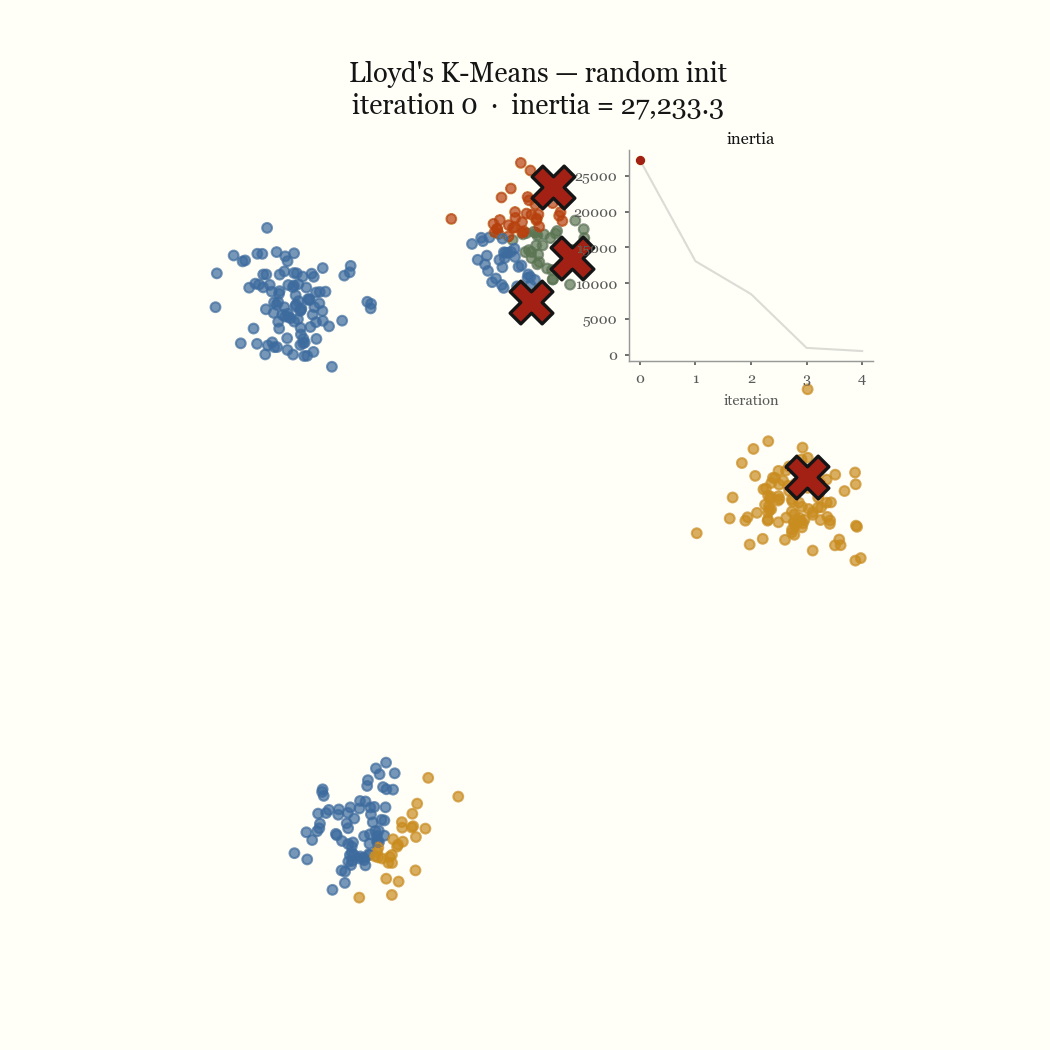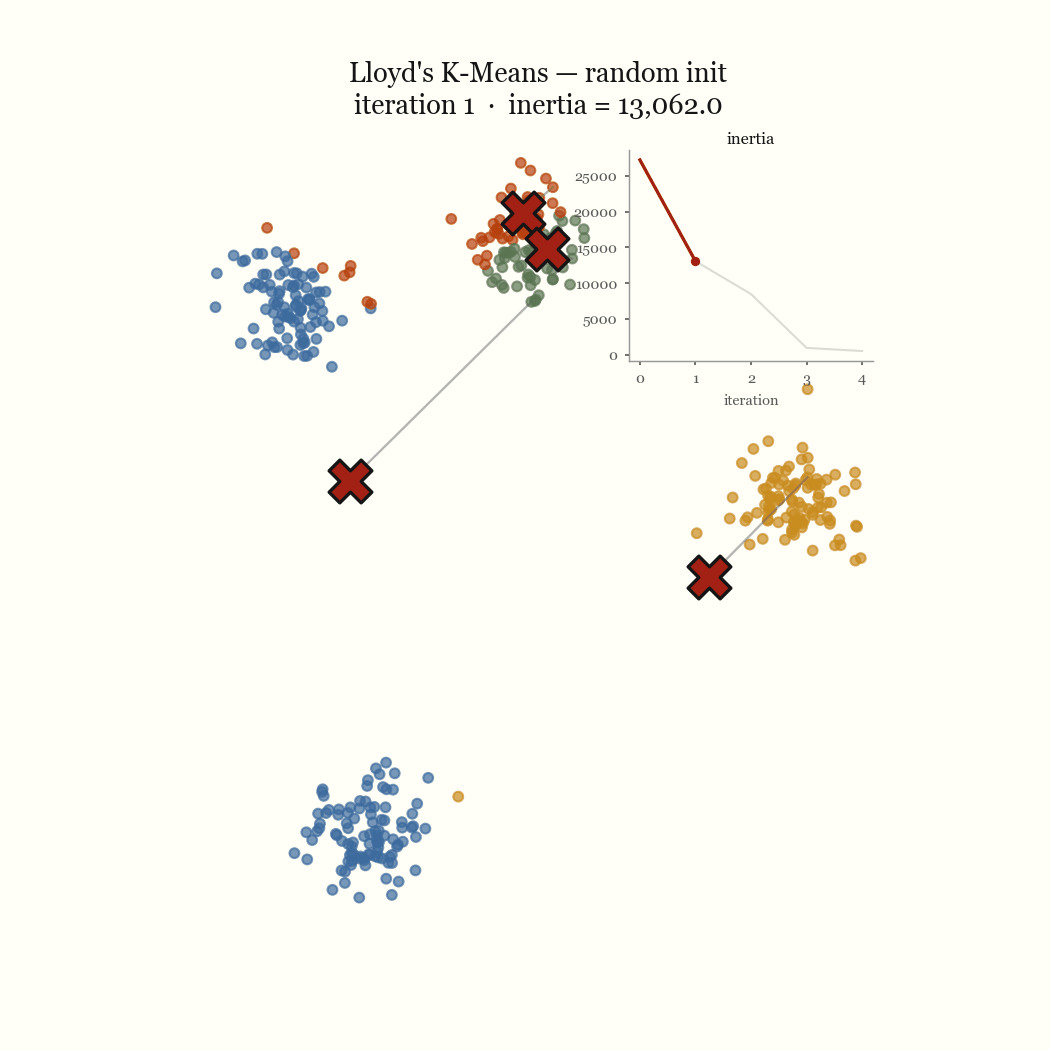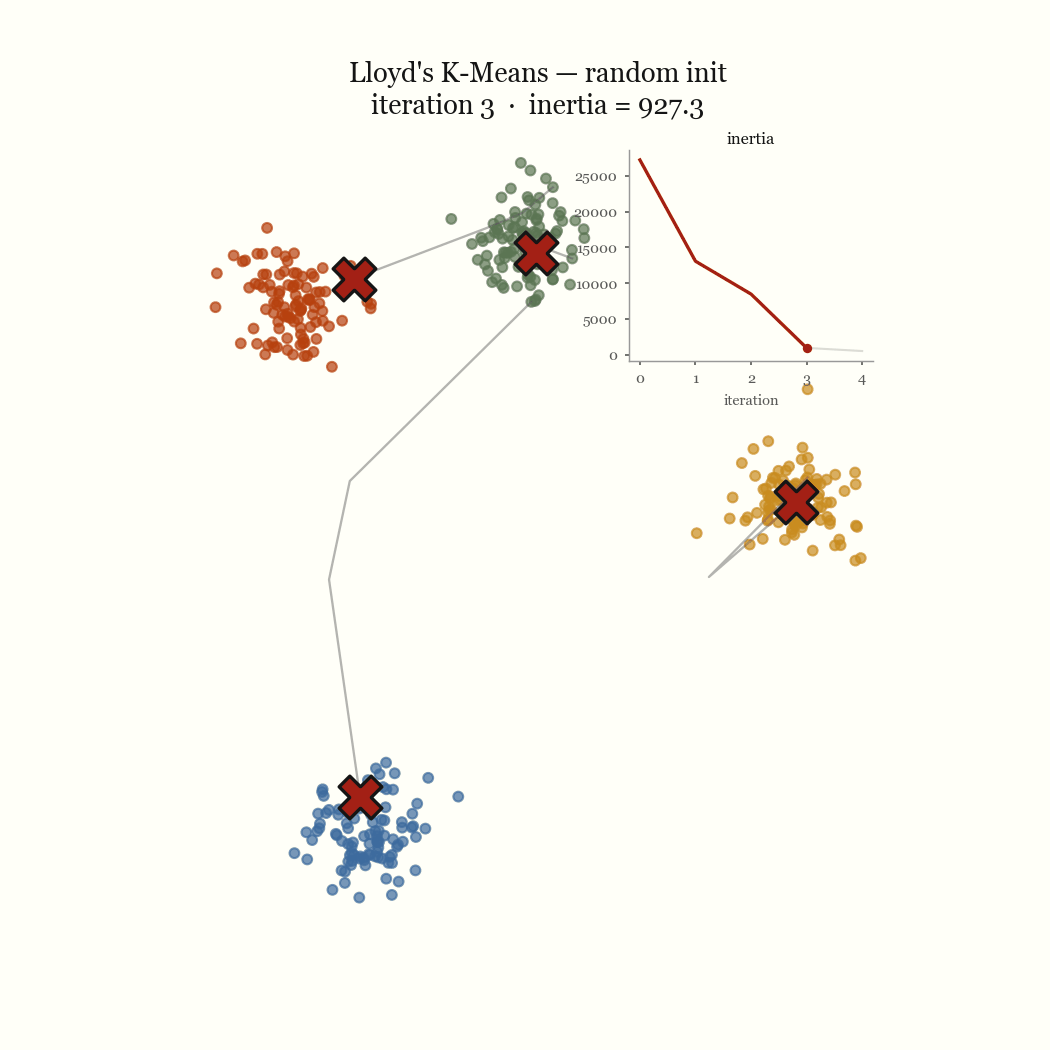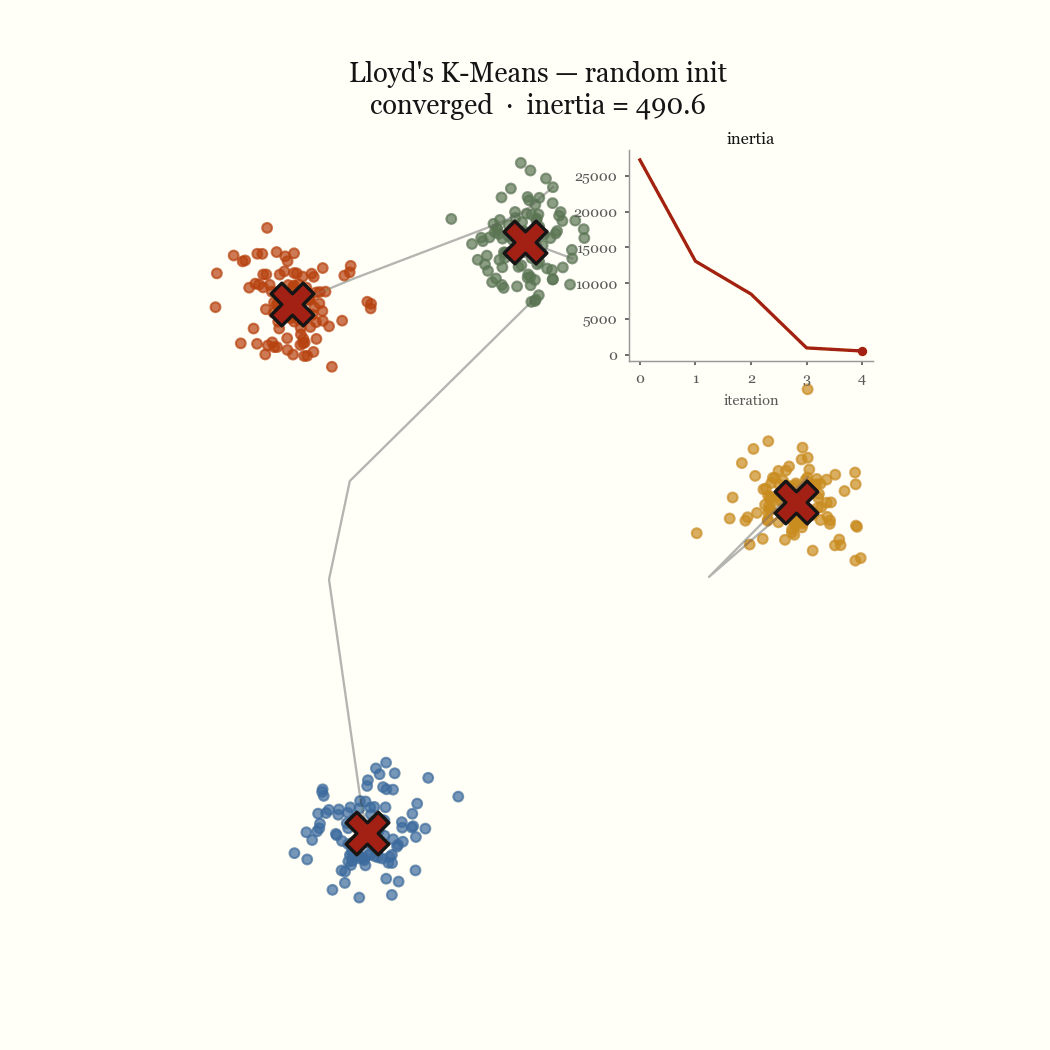
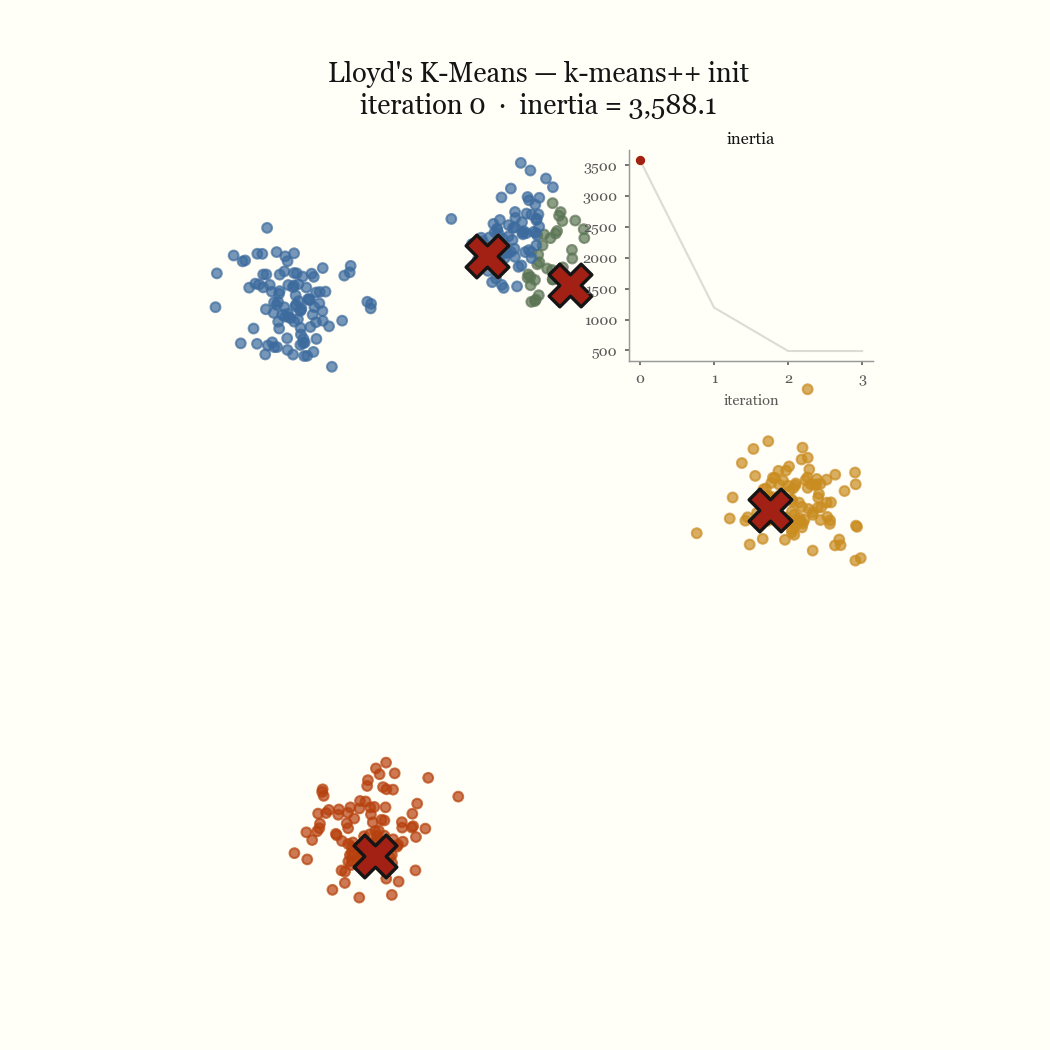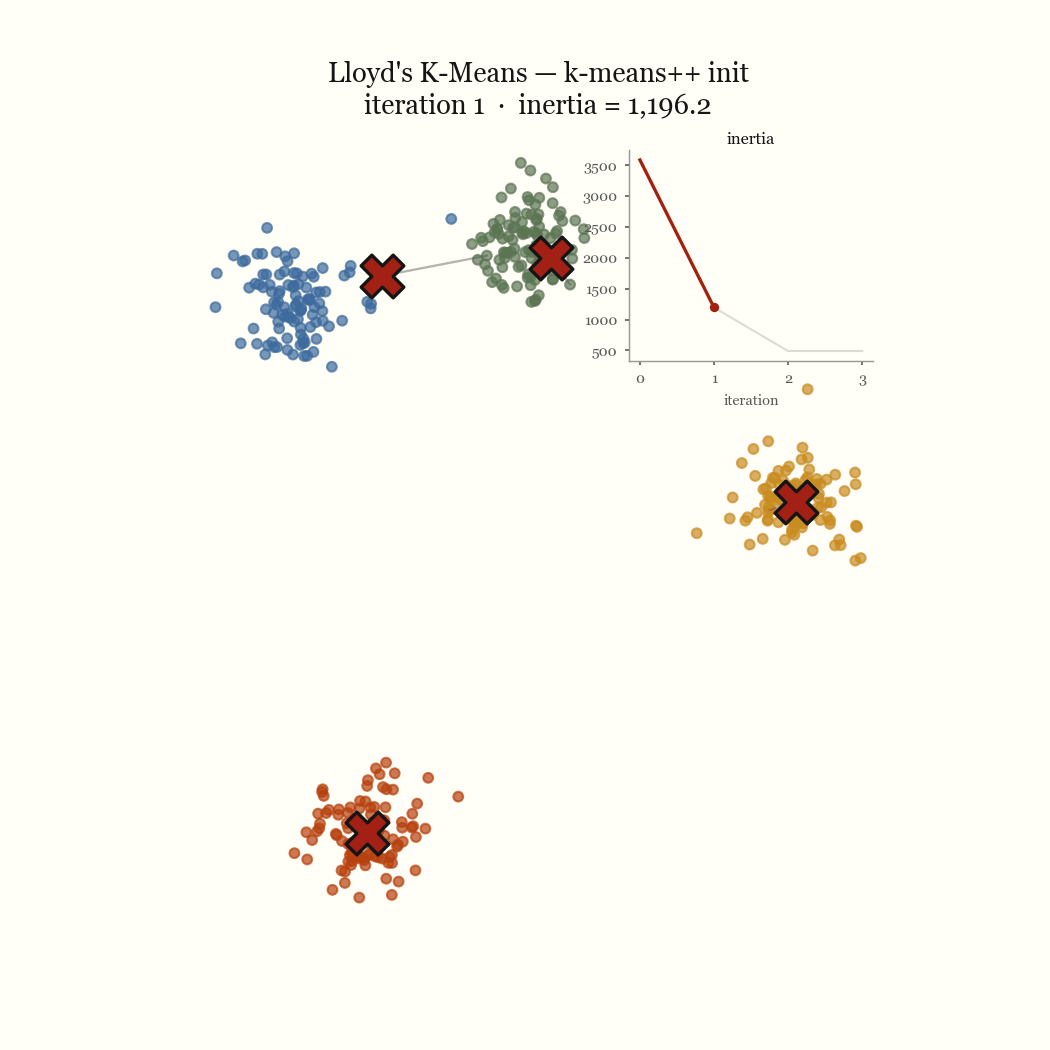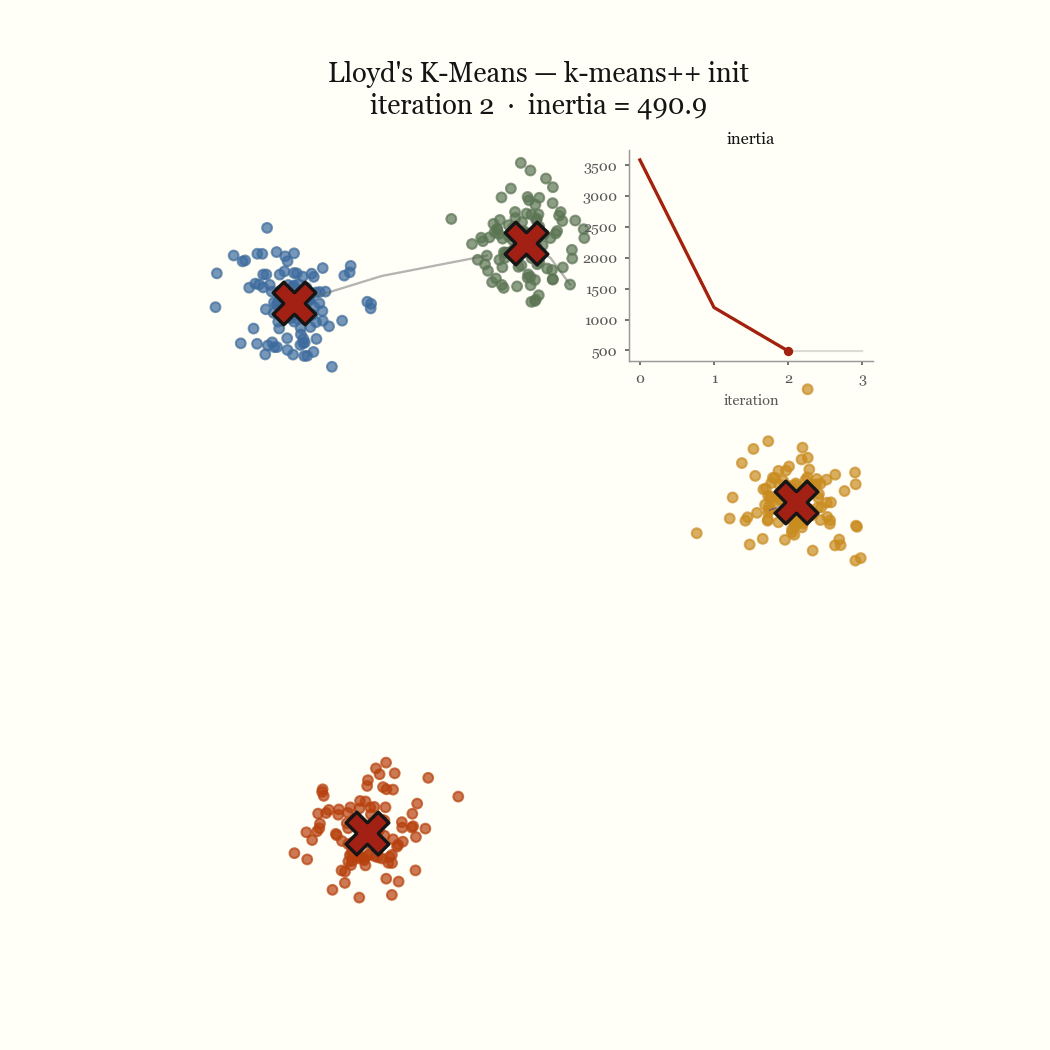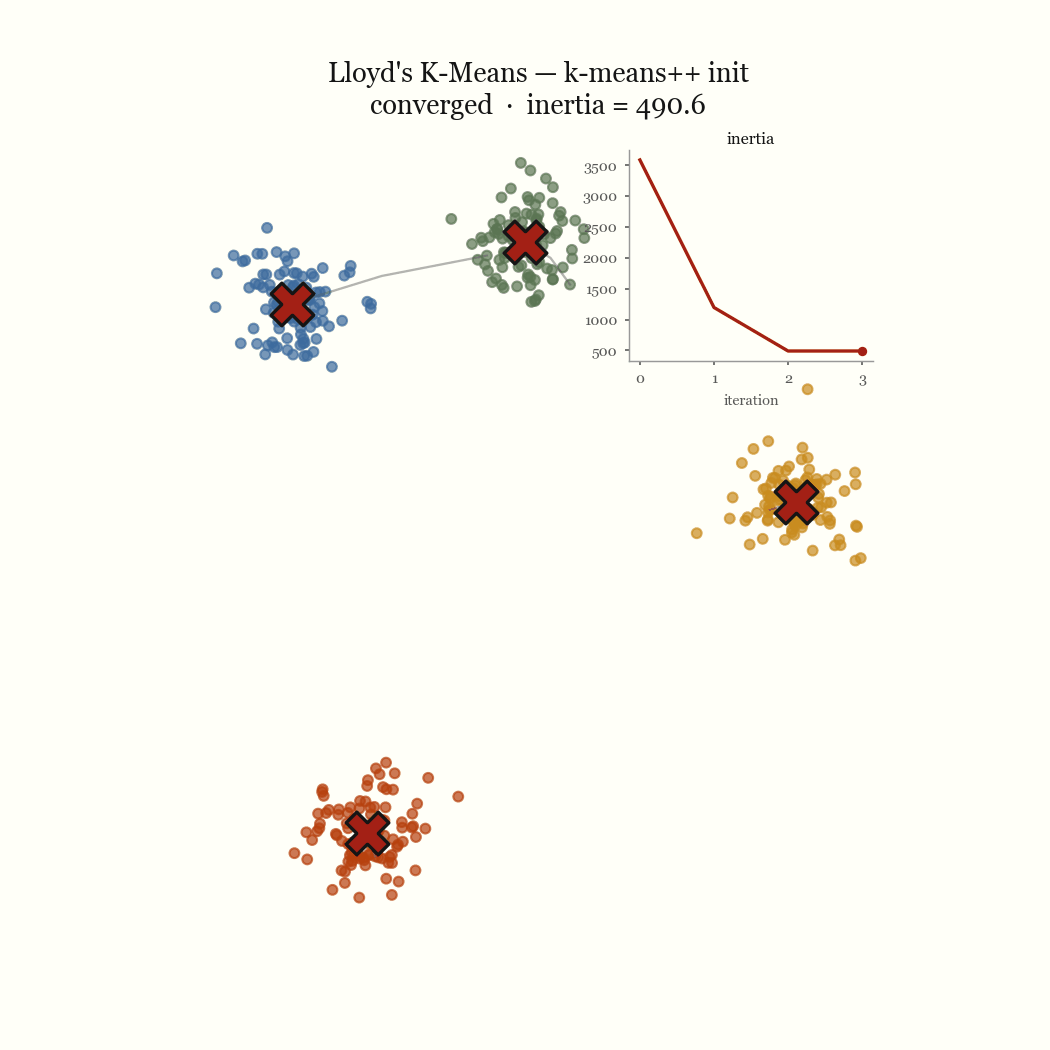
\[J \;=\; \sum_{j=1}^{k} \sum_{x \in C_j} \lVert x - \mu_j \rVert^2\]This quantity is the inertia, and it’s what the demo’s live chart plots per iteration. Finding the global minimum of \(J\) is NP-hard, so we don’t. Lloyd’s algorithm finds a local minimum cheaply by alternating between the two variables, and that alternation is the whole trick.
Lloyd’s algorithm as alternating minimization
Hold the centroids fixed and ask where each point should go. The term for point \(x\) is \(\lVert x - \mu_j \rVert^2\), and the only choice is which \(\mu_j\) to pair it with, so the best move is to send \(x\) to its nearest centroid. That’s the assignment step, and by construction it cannot increase \(J\): every point either keeps its centroid or moves to a closer one.
Now hold the assignments fixed and ask where each centroid should sit. For a fixed cluster \(C_j\), the value \(\mu_j\) that minimizes \(\sum_{x \in C_j} \lVert x - \mu_j \rVert^2\) is exactly the mean of the points in \(C_j\) — that’s the defining property of the arithmetic mean as the least-squares center. So the update step sets each centroid to its members’ mean, and it too cannot increase \(J\).Take the derivative of \(\sum_{x \in C_j}\lVert x - \mu\rVert^2\) with respect to \(\mu\), set it to zero, and you get \(\mu = \frac{1}{|C_j|}\sum_{x \in C_j} x\). The mean is not a heuristic here; it is the exact minimizer.

Two steps, each of which weakly decreases the same objective. So \(J\) is non-increasing across iterations, and it’s bounded below by zero. A bounded monotone sequence converges, and because there are only finitely many ways to partition \(n\) points into \(k\) groups, the algorithm reaches a fixed point in finite time rather than merely approaching one. That fixed point is a local minimum of \(J\). It is almost never the global one.
In code the loop is four lines:
- Initialize \(k\) centroids, random or k-means++.
- Assign every point to its nearest centroid under Euclidean distance.
- Update every centroid to the mean of its assigned points.
- If the labels (equivalently, the centroids) stopped moving, stop; otherwise loop.
The pure-Python reference in src/python_impl/kmeans.py is about 150 lines of NumPy and reads like that list. The Rust port is a faithful translation of the same four steps, with an opt-in Rayon path that changes only how steps two and three are scheduled.
Where it goes wrong: local optima and the wrong shape
Monotone descent guarantees you reach a minimum, not a good one. The objective \(J\) rewards compact, roughly spherical clusters, because squared Euclidean distance is isotropic. When the data’s real structure disagrees with that assumption, K-Means confidently returns the wrong partition and the inertia chart still flattens out, because it found a genuine local minimum of the objective it was given.
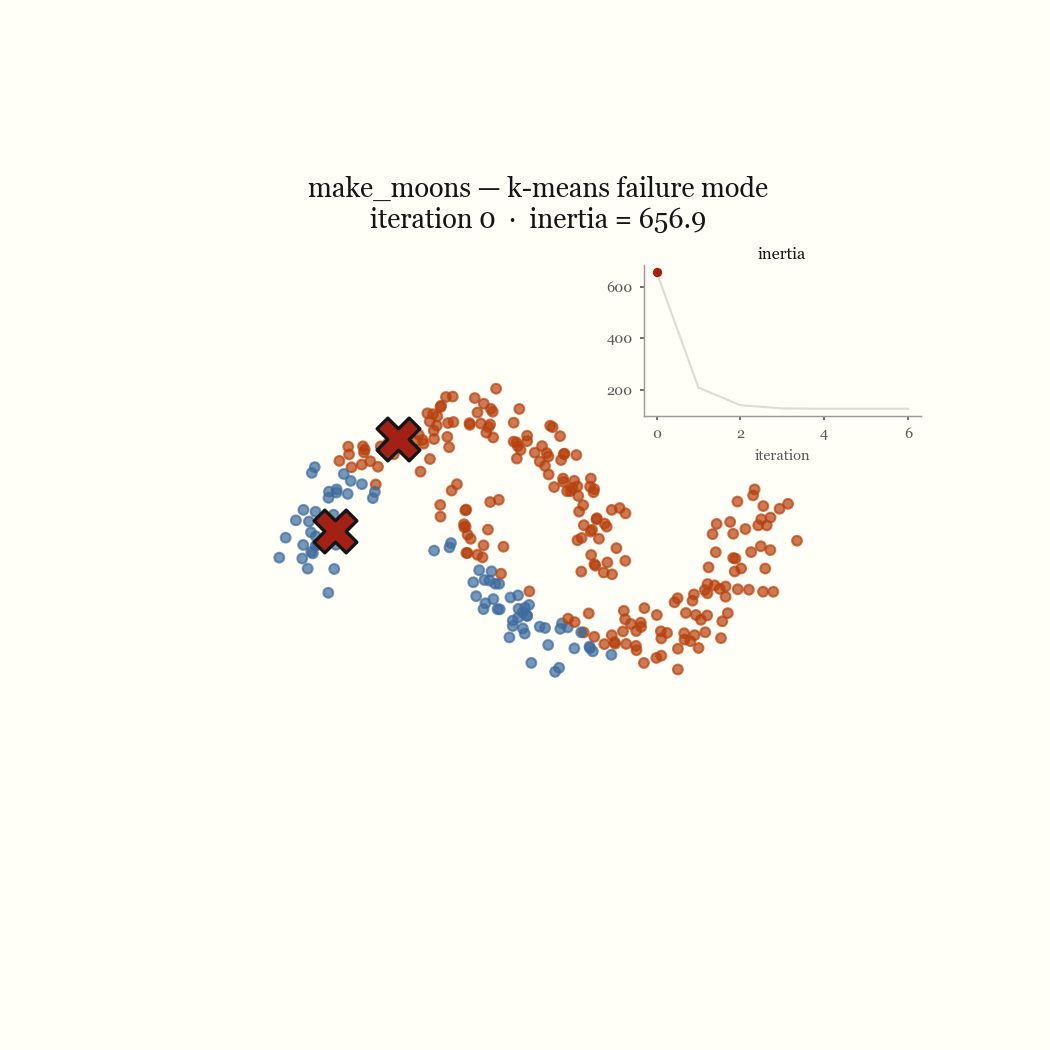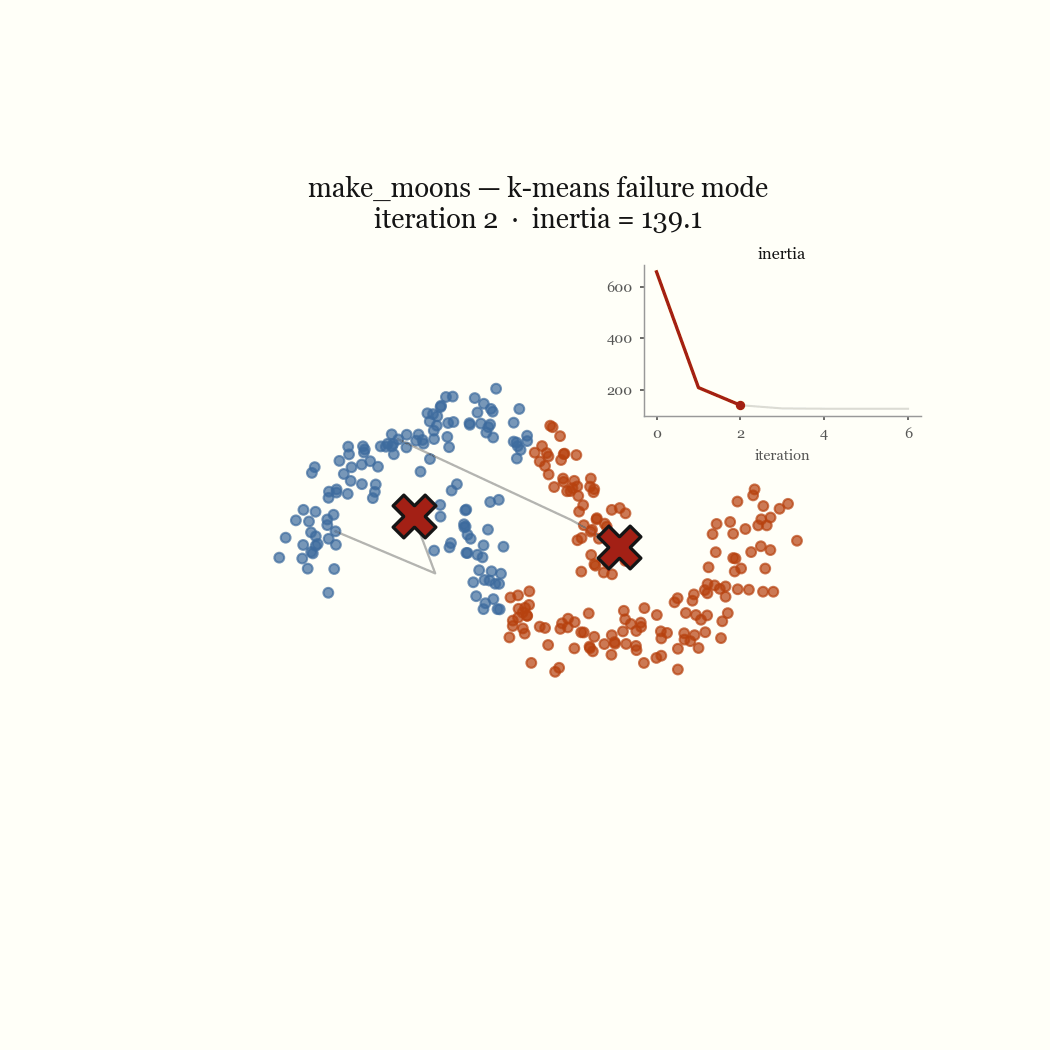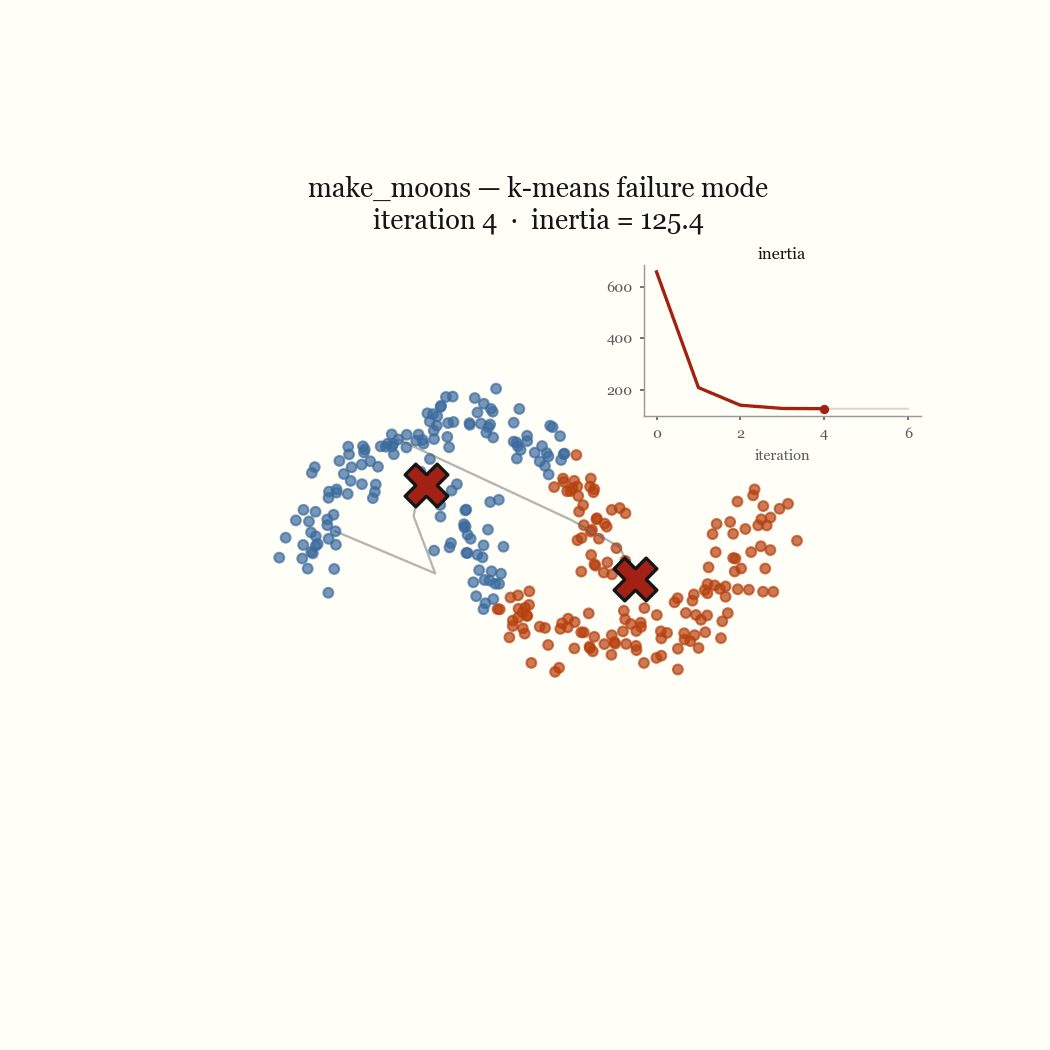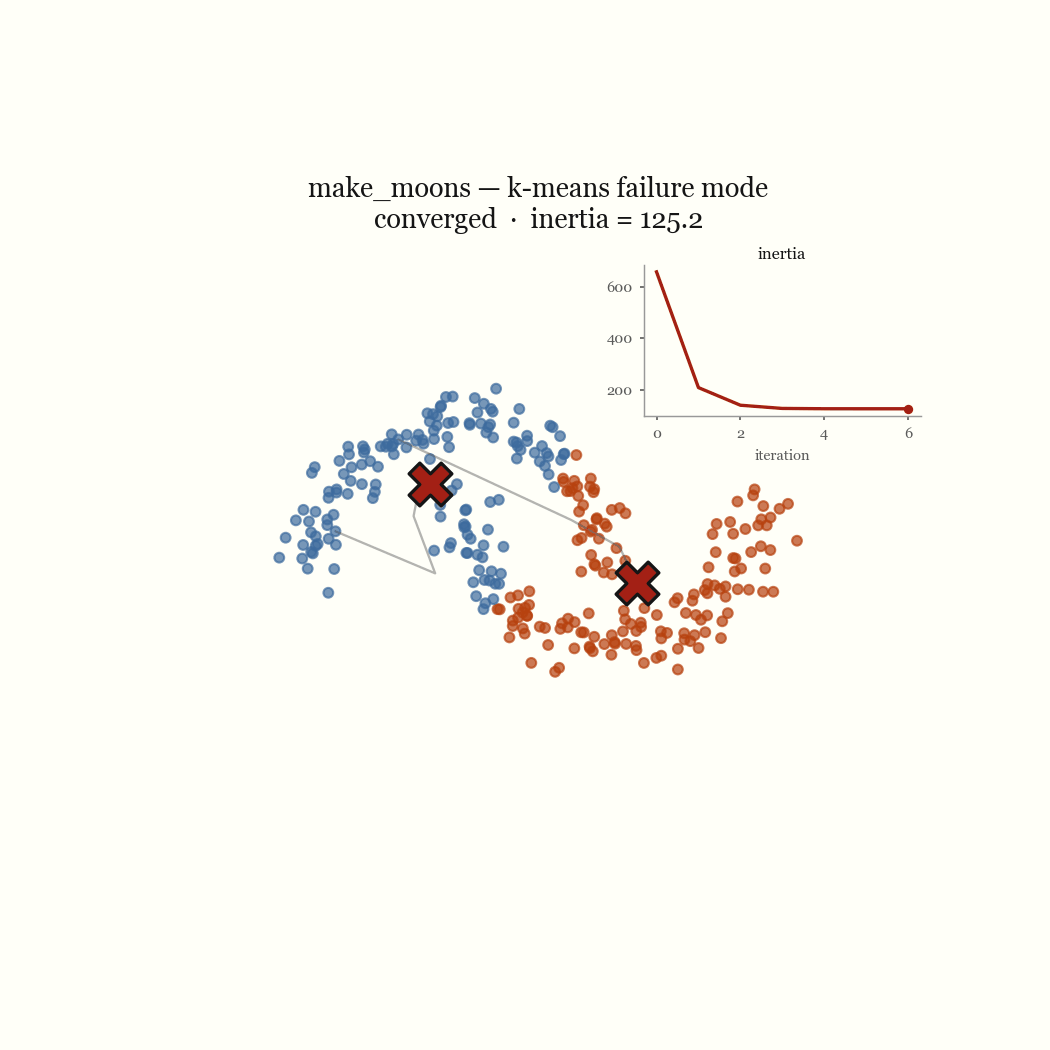
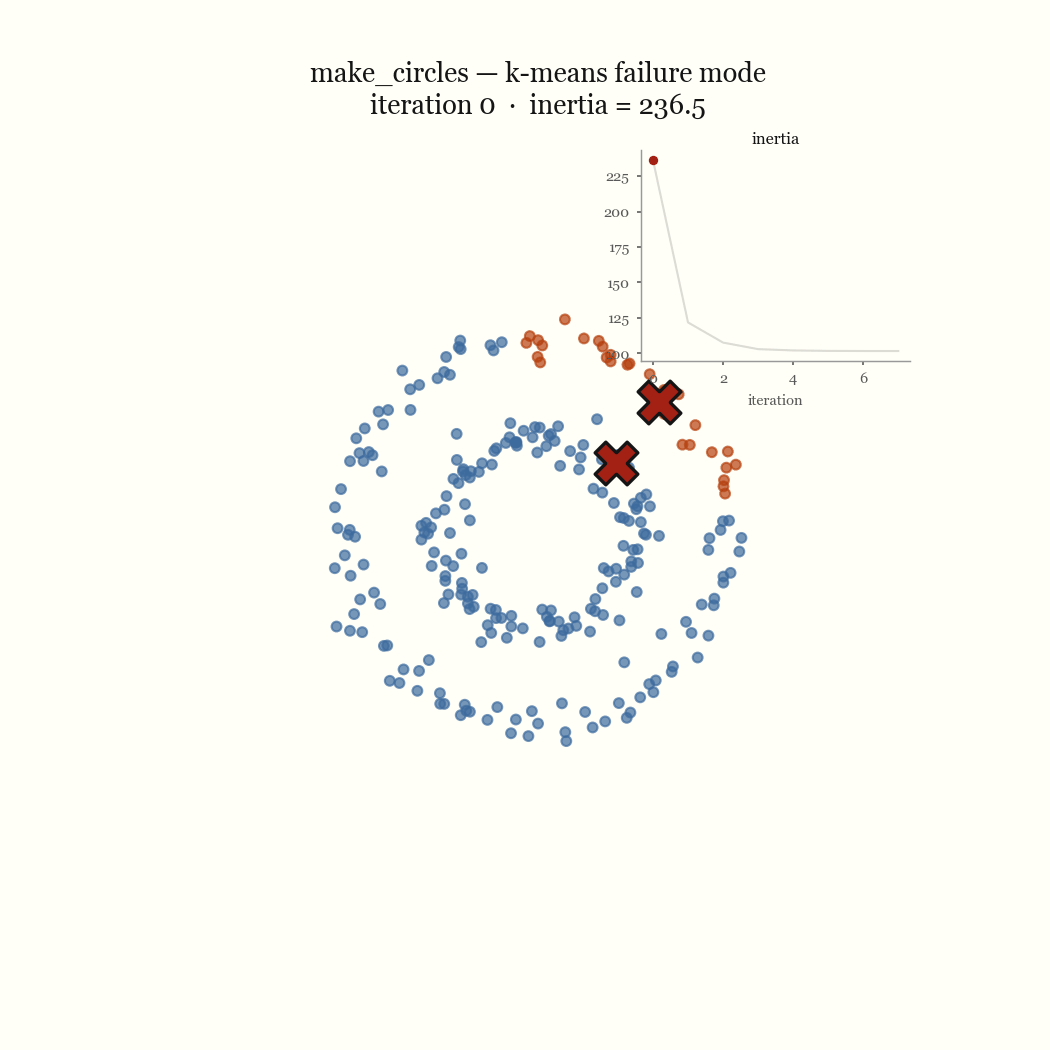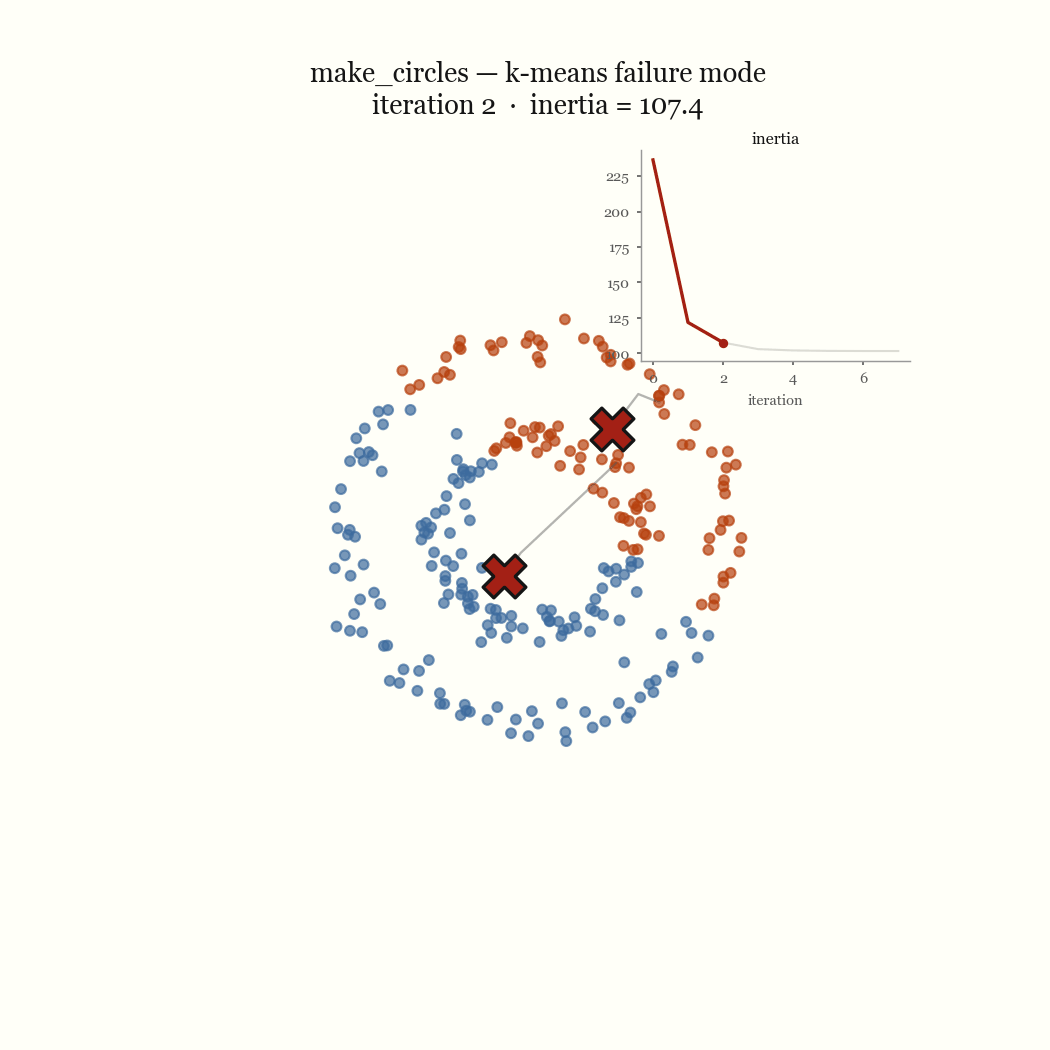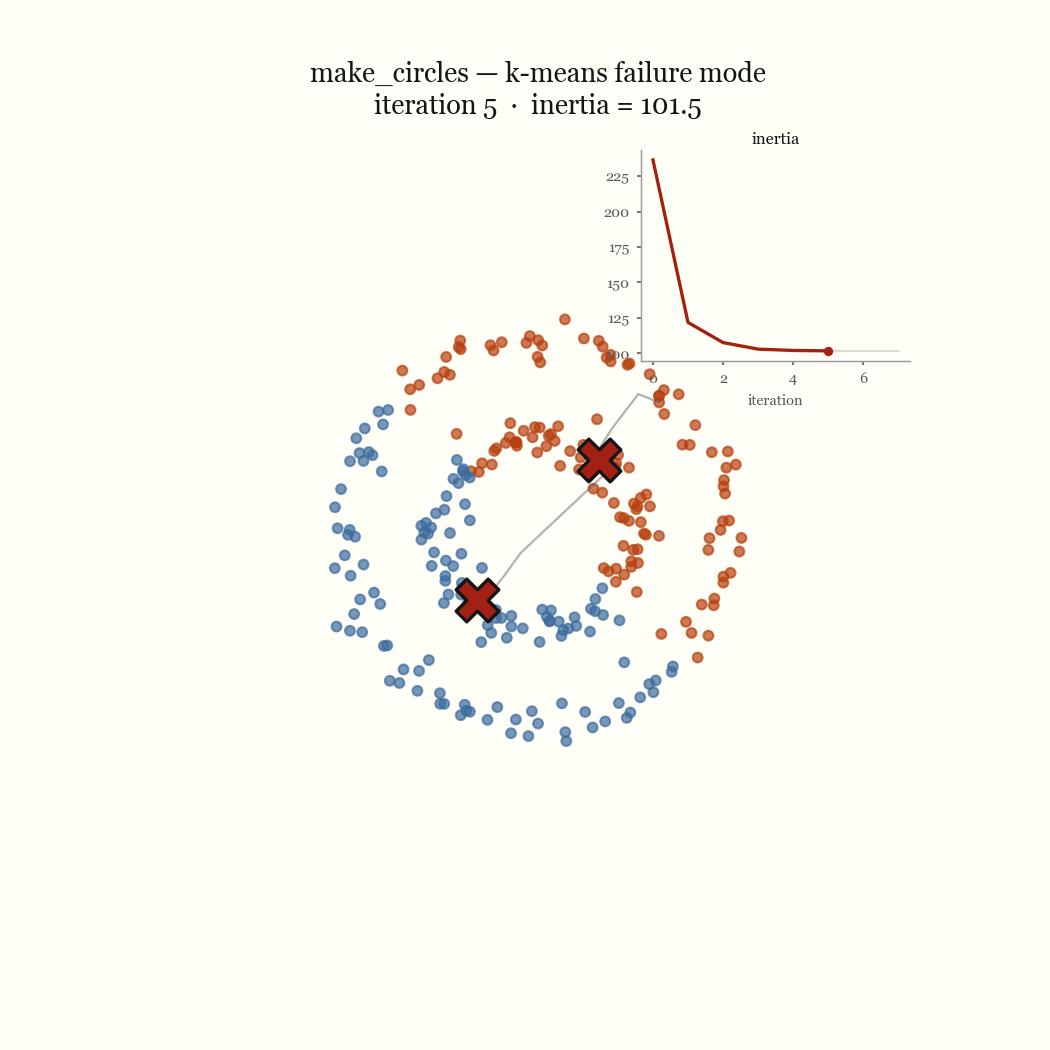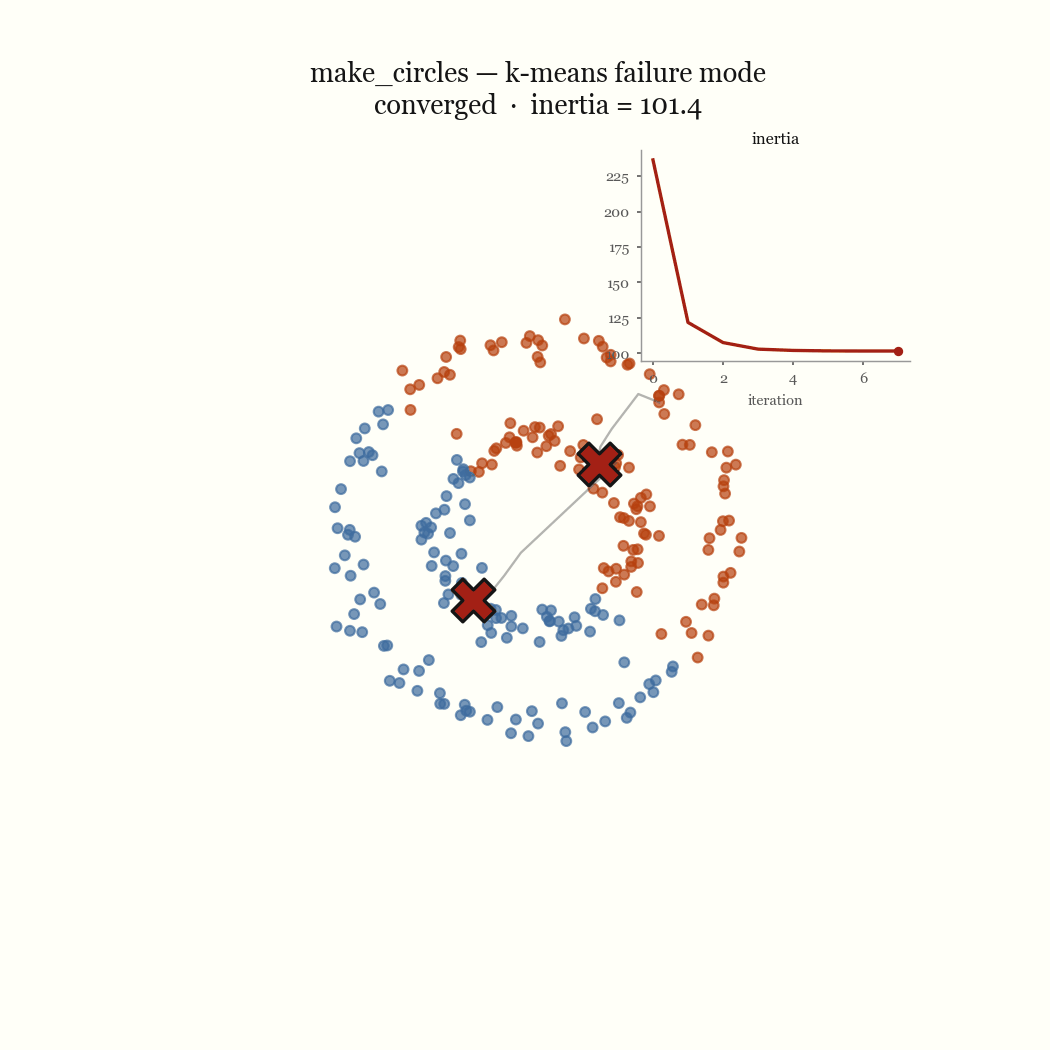
Two moons is the cleanest example of a failure that’s nobody’s bug. The two crescents are not linearly separable around a centroid, so any pair of centroids that minimizes squared distance will cut both moons in half rather than recover them. Concentric rings fail the same way for the same reason: K-Means partitions space into convex Voronoi cells, and a ring is not convex. The live demo lets you reproduce both in the browser. These are not initialization problems; no seeding fixes a model that draws the wrong kind of boundary.
The other failure mode is an initialization problem, and it’s the one worth fixing. If two initial centroids land in the same dense blob, the update step keeps them there, splitting one real cluster while a different real cluster goes unseeded and gets absorbed into a neighbor. That’s the pathological run above. The fix is to seed more carefully.
k-means++: spreading the seeds with D² sampling
Random initialization picks \(k\) points uniformly, which is exactly what lets two of them land in the same blob. k-means++ (Arthur and Vassilvitskii, 2007) changes the sampling distribution so the seeds repel each other. Pick the first centroid uniformly at random. Then, for each remaining centroid, sample a data point with probability proportional to the squared distance from that point to its nearest already-chosen centroid:
\[P(x) = \frac{D(x)^2}{\sum_{x'} D(x')^2}, \qquad D(x) = \min_{\mu \in \text{chosen}} \lVert x - \mu \rVert\]Points far from every existing seed are far more likely to be chosen next, so the seeds spread across the regions of the data instead of clumping. The Rust implementation does exactly this in initialize_kpp, building a WeightedIndex over the \(D^2\) weights and falling back to uniform only in the degenerate case where every weight is zero.It samples on \(D^2\) without taking the square root, since the square root is a monotone transform and doesn’t change the relative weighting. One fewer call per point per seed.

The payoff isn’t just empirical. Arthur and Vassilvitskii proved that k-means++ seeding alone, before Lloyd’s even runs, yields a clustering whose expected cost is within an \(O(\log k)\) factor of the optimal \(J\).D. Arthur and S. Vassilvitskii, “k-means++: The Advantages of Careful Seeding,” Proc. 18th ACM-SIAM Symposium on Discrete Algorithms (SODA), 2007, pp. 1027–1035. The bound is \(\mathbb{E}[J] \le 8(\ln k + 2)\,J_{\text{opt}}\). Uniform random seeding carries no such guarantee; it can be arbitrarily bad. That bound is the reason k-means++ is the default seeding for every implementation in this study, and it’s why the inertia comparison below comes out the way it does.

What it costs to run
One Lloyd’s iteration is dominated by the assignment step, which compares every one of \(n\) points against every one of \(k\) centroids in \(d\) dimensions. That’s \(O(nkd)\) work per iteration. The update step touches each point once to accumulate its cluster’s mean, \(O(nd)\), which the assignment cost swallows. Run it for \(i\) iterations and the whole fit is
\[O(n \cdot k \cdot d \cdot i).\]Three of those four factors are fixed by the problem, but \(i\) is where seeding earns its keep a second time: a good k-means++ start often converges in two or three iterations where a bad random start grinds for many more. The complexity also explains the shape of the parallel story. The \(nkd\) in the assignment step is an embarrassingly parallel map over points, so that’s what Rayon fans out. The update is a reduction, summing each cluster’s members and dividing, and reductions parallelize too, but the cross-iteration dependence in \(i\) does not. You parallelize within an iteration, never across them. That tension, and how far it actually gets us here, is the subject of the parallelism page.
A last note on how I score all of this. Throughout the study I measure clustering quality against the ground-truth labels the data was generated from, mostly with the adjusted Rand indexARI counts pairs of points that two labelings agree to put together or apart, then corrects for the agreement you’d expect by chance. It runs from a small negative number through 1.0; 1.0 is a perfect match up to relabeling, 0 is chance. and the normalized mutual information.NMI is the mutual information between the predicted and true labelings, normalized to \([0,1]\) by their entropies. It rewards labelings that share information regardless of how the clusters are numbered. Both are invariant to how the clusters happen to be numbered, which is exactly what you want when comparing four implementations that have no reason to agree on label order.