
Where the 15x went: benchmarking a Rust k-means rewrite
Published:
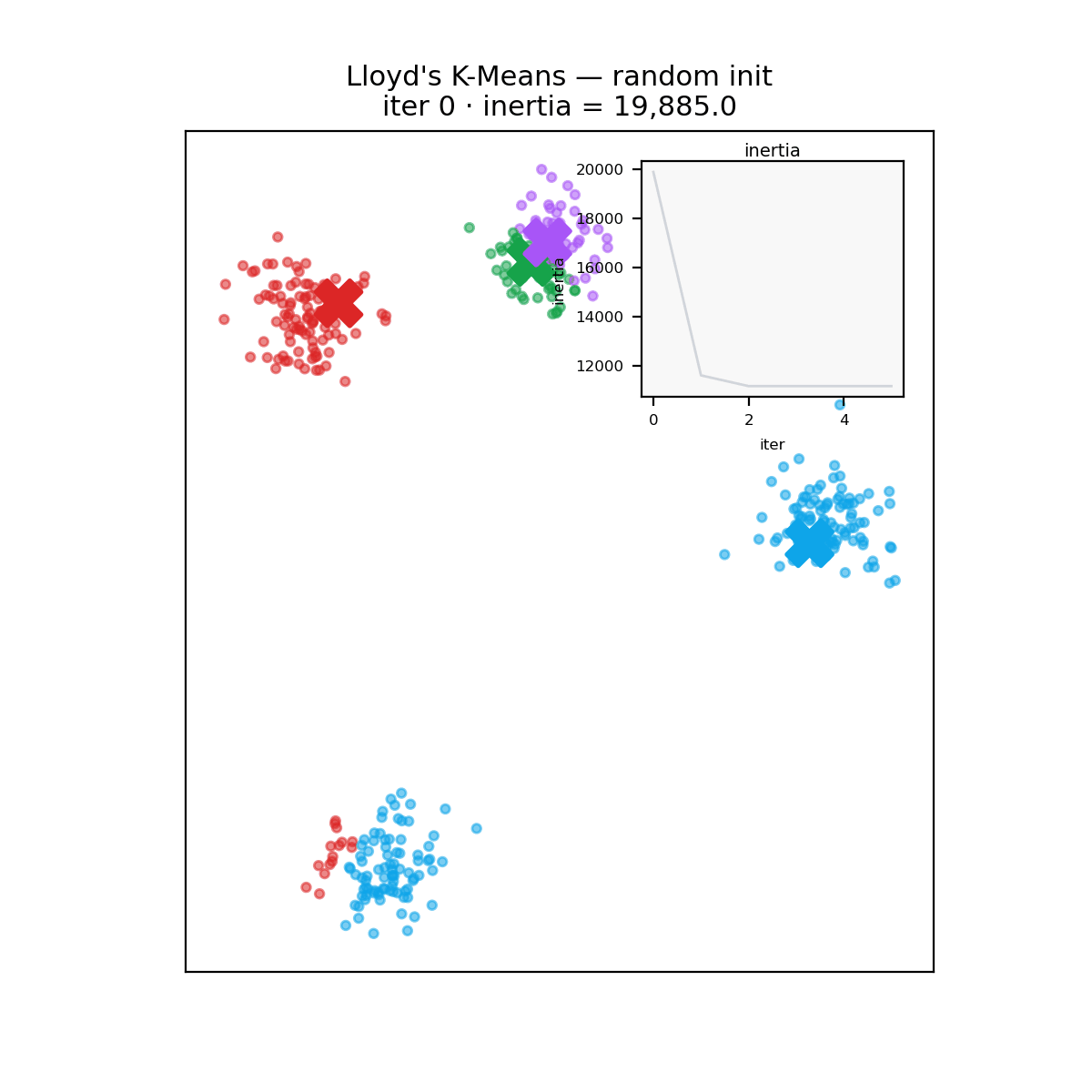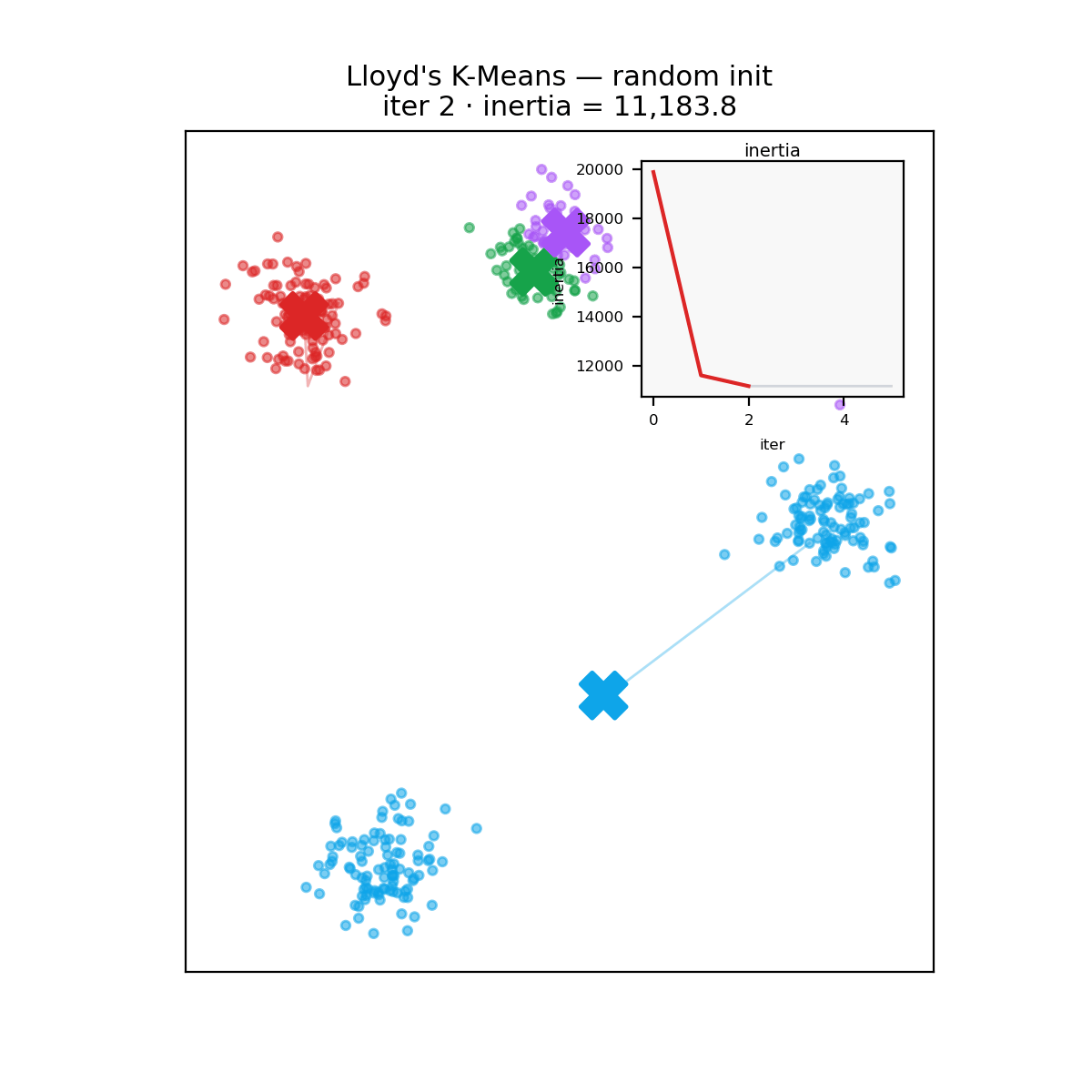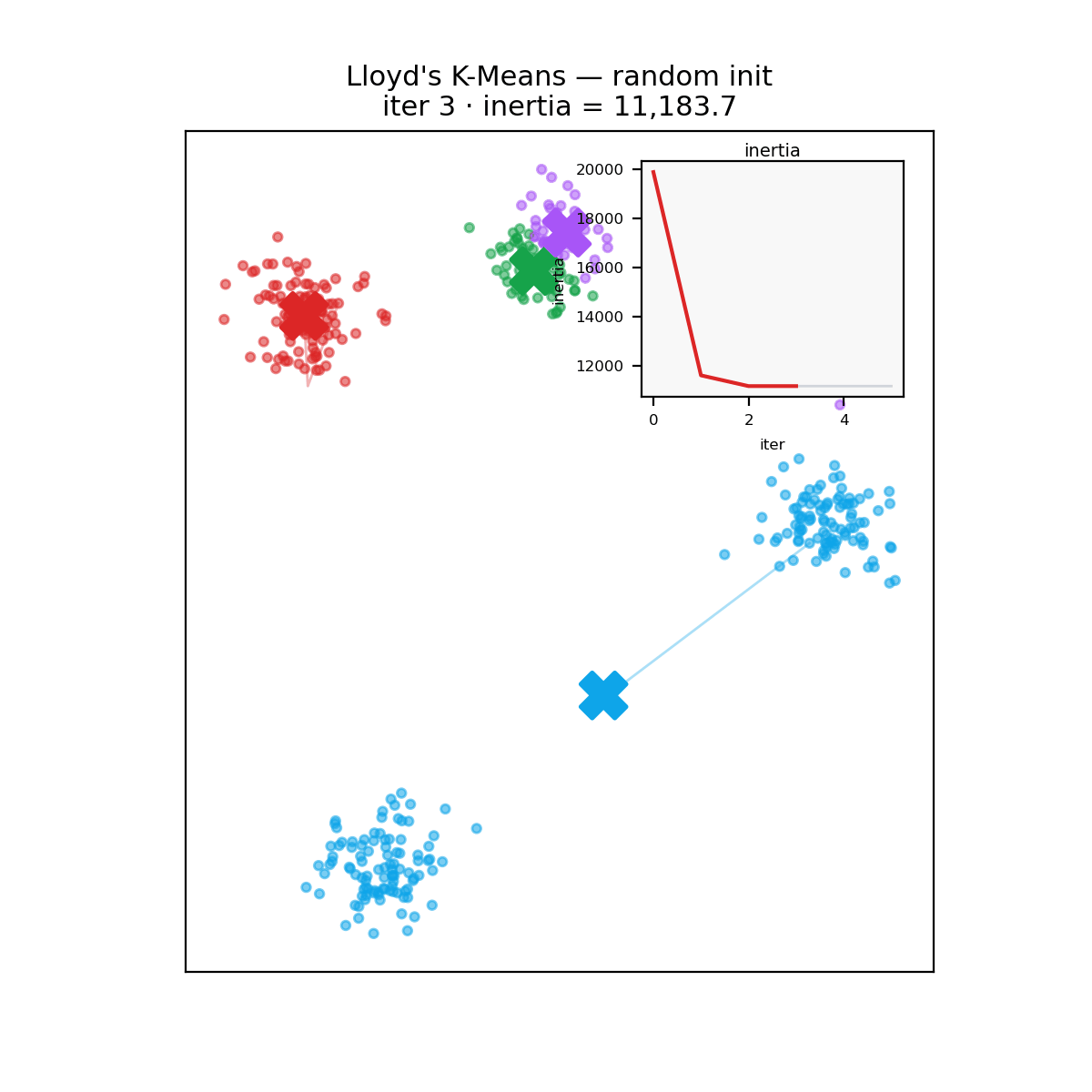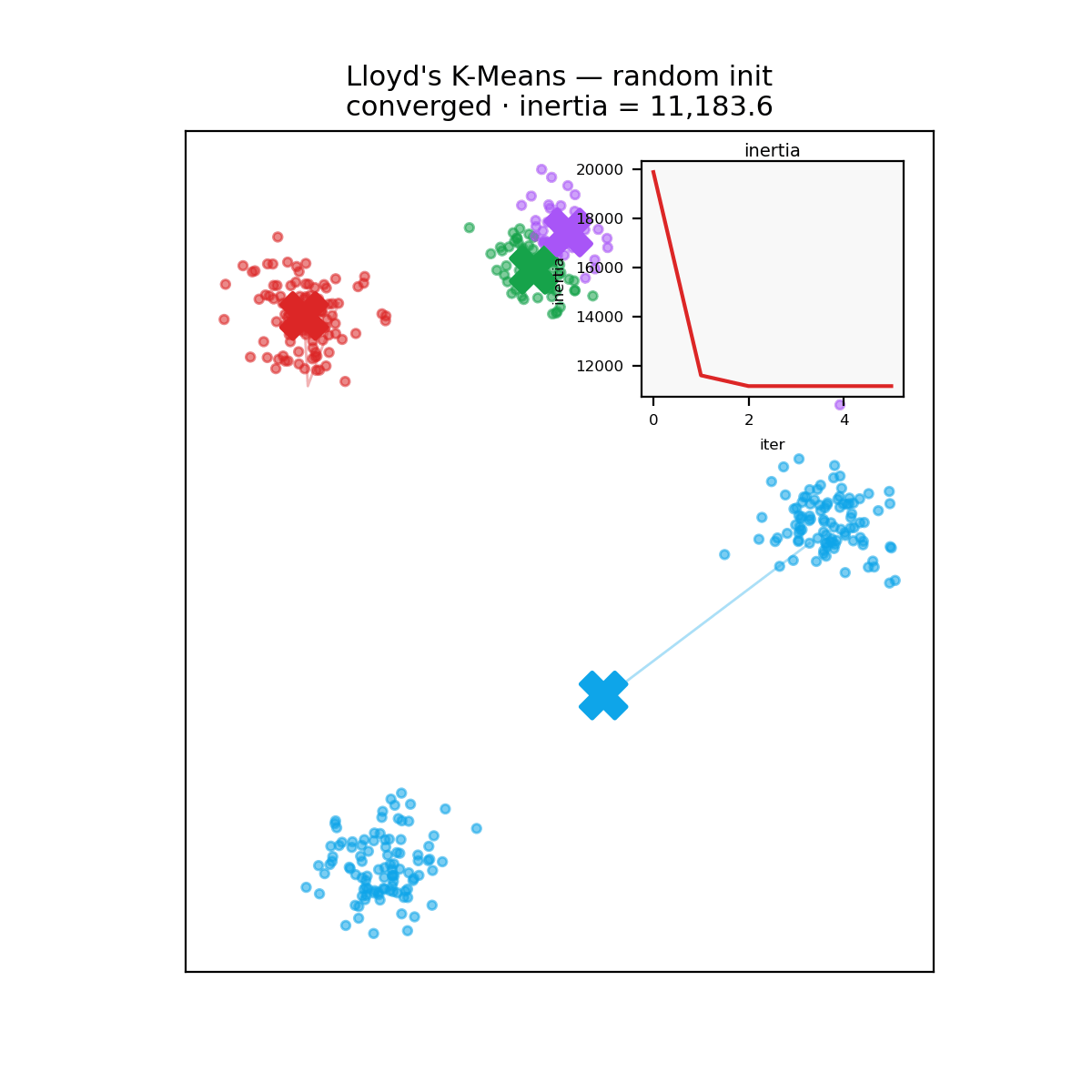
Clustering is the workhorse of unsupervised learning: given a pile of unlabeled measurements, find the groups. A biologist sequences ten thousand single cells and wants to know how many cell types are in the dish. An astronomer plots a million stars by color and brightness and looks for populations. In both cases the standard first tool is k-means, an algorithm from the 1950s that does nothing more than guess some group centers, assign every point to its nearest center, move each center to the middle of its points, and repeat.
It is also, very often, the thing that lights up red when you profile a pipeline. And when a hot loop lights up red, the modern reflex is to rewrite it in Rust.
I tried it, then measured it properly. At n = 1,000, a full elbow sweep (load the CSV, fit every k from 1 to K, write the results) takes pure-Python NumPy 0.43 s and scikit-learn 1.57 s. My hand-rolled Rust binary does it in 0.029 s. That’s roughly 15x over NumPy and 54x over the industrial, BLAS-backed scikit-learn, and it makes the rewrite look like a no-brainer. Then I gave all three engines the same initialization, swept out to a quarter-million points, and watched the 15x shrink to 3.5x. In one corner of the grid it reverses entirely.
Results at a glance (648 runs, Apple M4 Max, all engines on identical k-means++ init):
| Speed | Rust is a median 4.5x faster than NumPy, but the lead decays: 15x at n=1k, ~3.5x at n=256k. scikit-learn is slower than NumPy until ~128k. |
| Memory | Rust’s sampled peak RSS is ~11x under NumPy and ~22x under scikit-learn, at every size. The most durable win. |
| Threads | Rayon tops out near 1.3x over serial Rust. At n=1k, using all 14 cores is 28% slower than one. |
| Accuracy | With matched init, the engines tie: median ARI 1.0 across the board. The old “quality gap” was an init gap. |
The setup
One end-to-end CLI run per configuration: load CSV, fit k = 1..K, write CSV, exit. I time the whole subprocess rather than an in-process fit, because the subprocess is what a pipeline actually pays for. The grid is 9 sizes (1k to 256k, doubling) × 3 feature counts (2/8/32) × 2 cluster budgets (k_max 8 or 32) × 3 repeats, on synthetic Gaussian blobs. Three engines: pure-Python NumPy, hand-rolled Rust (with an optional Rayon-parallel mode), and scikit-learn. The fairness control matters most: every engine uses k-means++ initialization, and scikit-learn runs at n_init=1, a single start like everyone else. This is a rerun of an earlier experiment that didn’t control init, and that control changes one headline result, which I’ll get to.
Metrics are subprocess wall time, sampled peak RSS (polled every 10 ms, so a sampling estimate rather than a kernel max), and ARI/NMI against the ground-truth blob labels.
What k-means actually is
The algorithm predates most of computing. Stuart Lloyd worked it out at Bell Labs in 1957 as a quantization scheme for pulse-code modulation (the memo wasn’t formally published until 1982), and MacQueen coined the name “k-means” in 1967. What everyone runs today is still Lloyd’s loop:
- Assign each point to its closest centroid.
- Update each centroid to the mean of its assigned points.
Both steps minimize the same objective, the within-cluster sum of squares:
\[J = \sum_{i=1}^{n} \lVert x_i - \mu_{c_i} \rVert^2\]The assignment step minimizes $J$ over the labels $c_i$ with the centroids held fixed; the update step minimizes it over the centroids $\mu_j$ with the labels held fixed. Neither step can increase $J$, so the loop converges, though only to a local optimum. If you’ve trained anything with EM or alternating least squares, this is the same coordinate-descent shape.
The cost per iteration is $O(nkd)$: every point against every centroid across every dimension, dominated by the distance computation. And the distance computation hides a matrix multiply. Expanding the square,
\[\lVert x_i - \mu_j \rVert^2 = \lVert x_i \rVert^2 - 2\, x_i \cdot \mu_j + \lVert \mu_j \rVert^2,\]and the cross term for all pairs at once is $X M^\top$, an $n \times k \times d$ GEMM. The two norm terms are cheap, one pass each over the points and the centroids; the cross term carries the whole $O(nkd)$ cost. That split is why scikit-learn is fast at scale: it hands the dominant term to BLAS, the matrix-multiply kernels that have been tuned for decades to keep data in cache and saturate SIMD units.
So the three engines run identical math with radically different execution profiles. The pure-Python NumPy version loops over centroids, filling one column of the distance matrix at a time with np.linalg.norm(X - centroids[k], axis=1). The Rust version runs explicit loops over its own data, no interpreter, no per-operation allocations. scikit-learn routes through the GEMM. Same arithmetic, three memory stories.
Speed
Across the full sweep, Rust is a median 4.51x faster than pure-Python NumPy. That 4.51x is a median of paired ratios: each of the 162 benchmark datasets (size × features × clusters × repeat) gets one Python-time-over-Rust-time ratio, and the median is taken across those. The mean of the same ratios is 6.58x, pulled up by the small-n cells where Rust shines, and the ratio of overall median runtimes is 4.02x. I lead with the median for the same reason you report p50 latency instead of the average: it describes the configuration you’ll actually hit, not a blend skewed by the best cases.
One piece of chart literacy before the figures: both axes below are logarithmic, and on log-log axes a power law plots as a straight line whose slope is the growth exponent. Flatter line, gentler scaling.

Pooled across the grid, Rust runs from 0.029 s at n=1k to 4.13 s at n=256k. Its fitted slope is 0.902 (R² 0.993), close to linear and slightly under it, about what you’d expect from naive $O(nkd)$ loops picking up some cache pressure. NumPy’s slope is 0.599 (R² 0.911) and scikit-learn’s is a near-flat 0.249 (R² 0.831). These are descriptive fits over size-medians, not clean algorithmic exponents, hence the R² values. But the ordering is the story: the more fixed overhead an engine carries, the less it notices additional rows.
That’s why the speedup decays.

Rust’s lead falls from 14.5x at n=1k to about 3.5x at n=256k, never dropping below 3x. scikit-learn runs the opposite direction: 0.27x at n=1k, climbing to 1.80x at n=256k. At small n, library start-up and BLAS’s fixed overhead dwarf the actual work (and at n_init=1 none of that can be blamed on restarts). The two curves converging from opposite sides is the picture to keep in mind whenever someone quotes a single speedup number for a rewrite.
The corner scikit-learn wins
My first, uncontrolled run had scikit-learn “overtaking Rust at n=128k,” full stop. The rerun sharpens that considerably. Pooled over the grid, Rust never loses to scikit-learn at the median, not even at 256k. scikit-learn is faster in exactly 4 of 54 grid cells, and all four have k_max=32 and n ≥ 128k.
The crossover doesn’t care much about feature count: two of those four cells are at f=2, the skinniest data in the grid. What tips the balance is rows times clusters, the $n \times k$ face of the distance computation, more than the full GEMM volume. In the heaviest slice (f=32, k=32) the crossing is visible in the figure above: 8.0 s vs 9.4 s at 128k, 15.4 s vs 20.8 s at 256k. At the light end, few features and few clusters, Rust beats scikit-learn by 6–65x with no crossover in sight.
scikit-learn isn’t running a smarter algorithm here. It’s the same Lloyd iteration, with the dominant term handed to a GEMM that keeps the distance block in cache and saturates the vector units. My Rust loses that corner because my loops are naive. A BLAS-backed Rust (an ndarray GEMM for the cross term) would very likely take it back; the ceiling was my loops, not the language.
What threads buy
The most seductive pitch for a Rust rewrite is “add Rayon, get 14 cores.” So I added Rayon and swept thread counts at every size.

Peak speedup climbs with n and plateaus near 1.3x (1.318x at n=256k, 1.286x at n=64k). At small n it’s actively harmful: n=1k peaks at 1.09x with a single worker and falls to 0.725x at 14 threads. Across the sweep the parallel path sustains a median of about 1.87 effective cores. For completeness, against Python the parallel build is about 5.1x at the median, but that’s mostly the serial 4.5x with the modest thread gain riding on top.
Two things cap it. First, granularity: the elbow sweep fits k = 1..K, so most fits are small-k with little arithmetic per point, and each Lloyd step has to process enough points to amortize Rayon’s split/join overhead. Second, layout: the data lives as an array of structs, a Vec<DataPoint> where every point owns its own heap-allocated Vec<f64>. The inner loop is pointer-chasing, so it’s memory-bandwidth-bound, and a handful of cores saturate the bandwidth while the rest add coordination cost.
Worth retiring a myth while I’m here: none of this is about Python’s GIL. NumPy releases the GIL inside its C loops, which is exactly why BLAS-backed calls can use multiple cores. The pure-Python baseline stays on one core simply because a serial Lloyd loop never asks for more. The GIL is the wall when you point threading at CPU-bound Python code; that’s not what’s happening in any of these engines.
Memory
The speed advantage has a ceiling. The memory advantage doesn’t.
Median sampled peak RSS: Rust 9.3 MB, NumPy 104.9 MB, scikit-learn 206.9 MB. That’s 11.3x leaner than NumPy and 22.2x leaner than scikit-learn. Normalized per 1,000 samples it’s 0.61 MB vs 7.41 vs 12.63. There is no size at which this flips.

The mechanism is the flip side of vectorization. In Python, “vectorized” concretely means “allocate a big array and let C fill it”: the NumPy engine materializes an N×k float64 distance matrix every single iteration, and that array is the memory bill. It’s why NumPy’s footprint eventually overtakes scikit-learn’s at n ≥ 128k (405 MB vs 397 at 128k, 759 vs 508 at 256k) even though scikit-learn carries a far heavier fixed base of interpreter and imports; sklearn’s chunked kernels never build the full matrix. Rust doesn’t build it either. Its assignment step walks each point against the centroids holding only a running nearest-index, so peak memory tracks the data itself.
One correction to my earlier write-up, since I’d guessed wrong about the cause: the Rust win is not about a tight cache-local matrix. As mentioned above, the layout is an array of structs with a heap Vec<f64> and a string id per point. The memory advantage comes entirely from never allocating the distance matrix. A flat contiguous Vec<f64> is the optimization I left on the table, and it would help the parallel story and the large-n slope too.
Accuracy, and the init effect
This is where the rerun changes a conclusion. In my first pass the hand-rolled engines used random init while scikit-learn used its default ten restarts, and Rust posted the worst clusterings of the three (ARI 0.66 against scikit-learn’s 1.0). I briefly believed the rewrite traded accuracy for speed. It didn’t. The gap was the experiment design.
With every engine on the same k-means++ init, the median ARI is 1.0 for all of them, and the means barely separate: scikit-learn 0.9988, Python 0.9802, Rust 0.9742. Internal metrics agree (silhouette 0.93/0.92/0.92; Davies-Bouldin 0.10/0.18/0.19).

scikit-learn’s remaining edge is the worst case. The natural suspect is its greedy k-means++ variant, which tries several candidate seeds at each step and keeps the best: extra robustness on the hardest configs. (Convergence tolerance and empty-cluster handling differ too, so the 0.12 isn’t all seeding.) It’s a sturdier start, not a faster engine.
The k-means++ idea, due to Arthur and Vassilvitskii in 2007, is worth knowing on its own. Instead of dropping k seeds uniformly at random, pick each new seed with probability proportional to its squared distance from the nearest seed already chosen:
\[p(x) \propto D(x)^2\]Far-away regions get seeded, clumps don’t, and a single start usually lands near a good basin (the paper proves an O(log k) bound on expected cost). In a standalone pure-Python ablation with 10 seeds per config, switching random init to k-means++ cut final inertia by 37% to 54%, and the benefit grows with k and dimension.

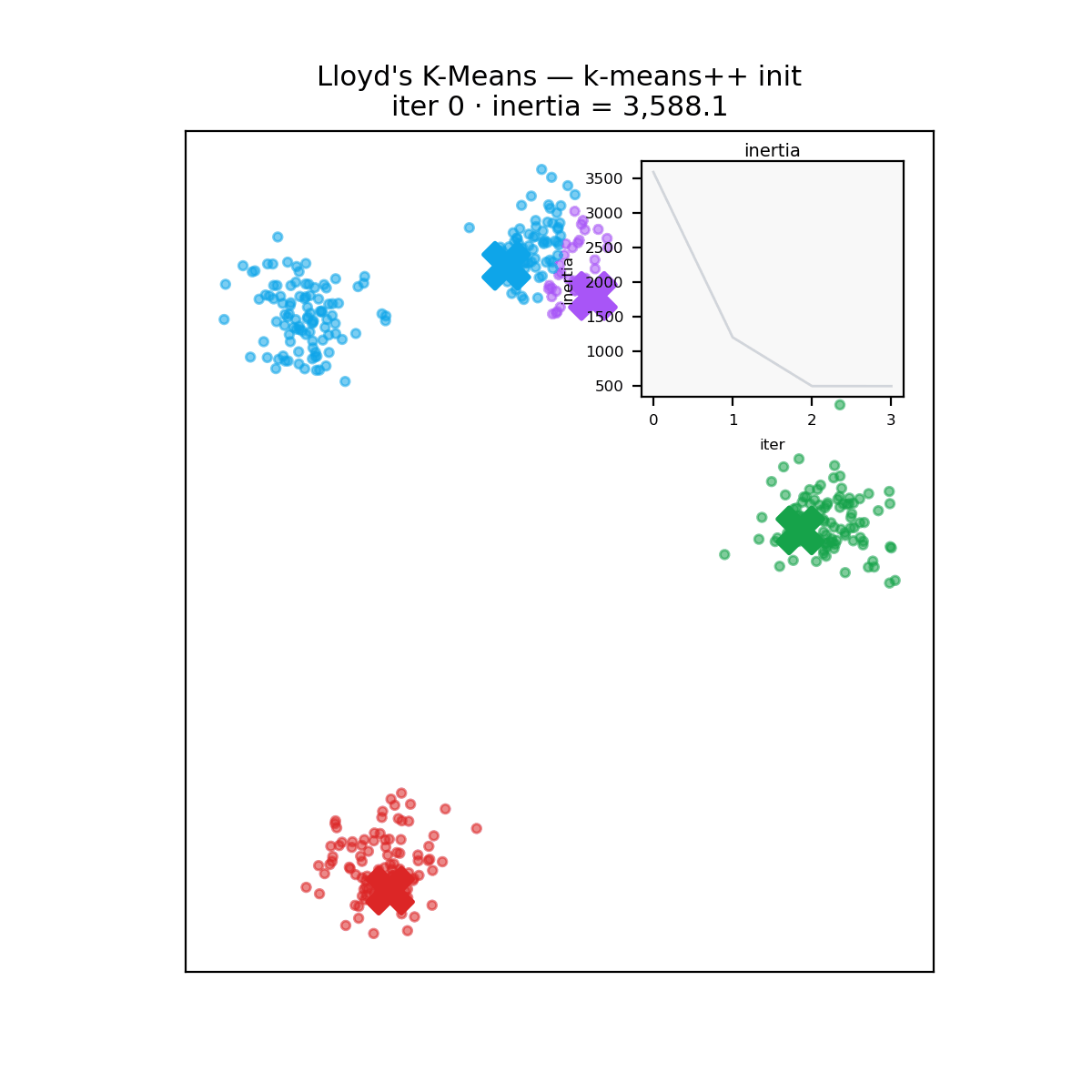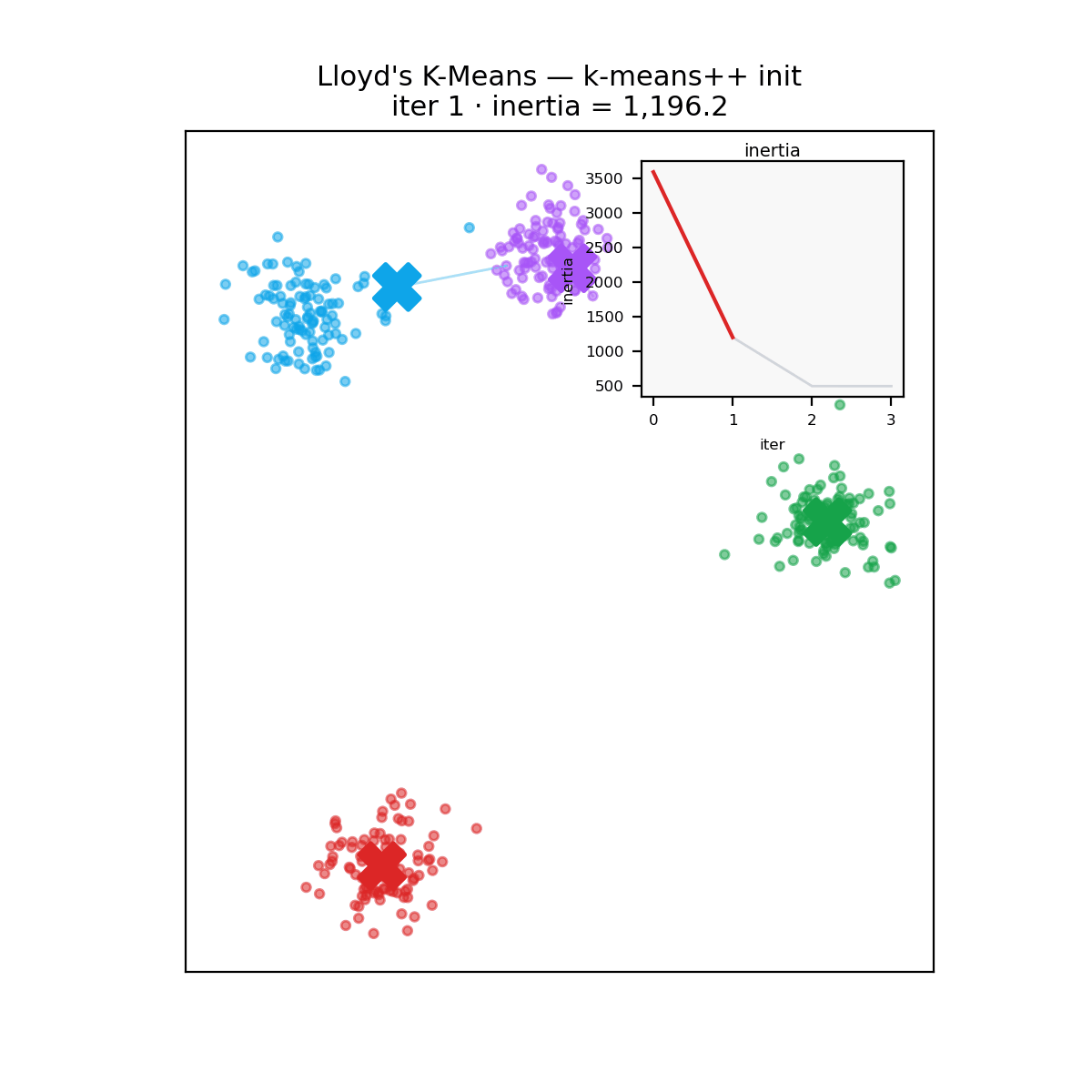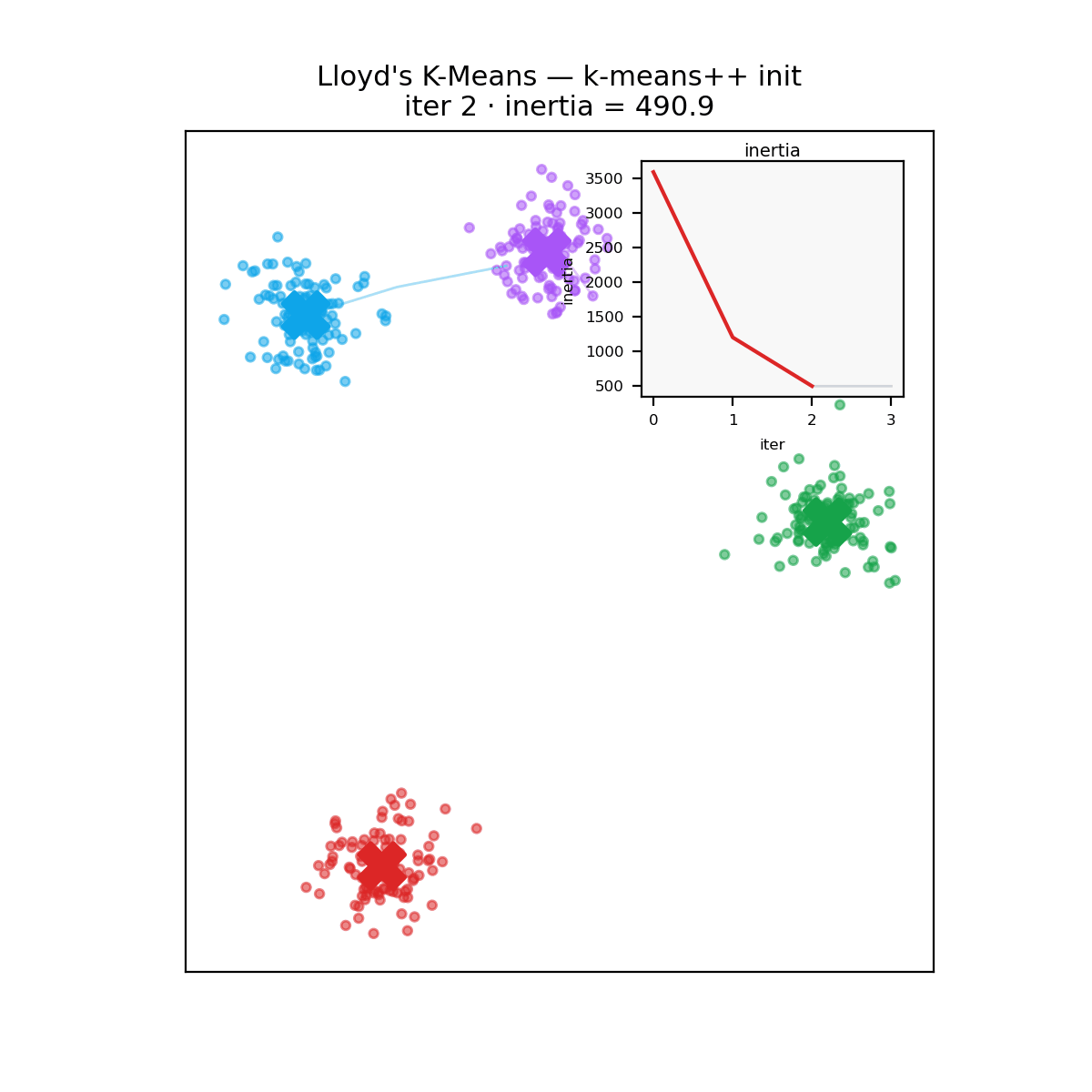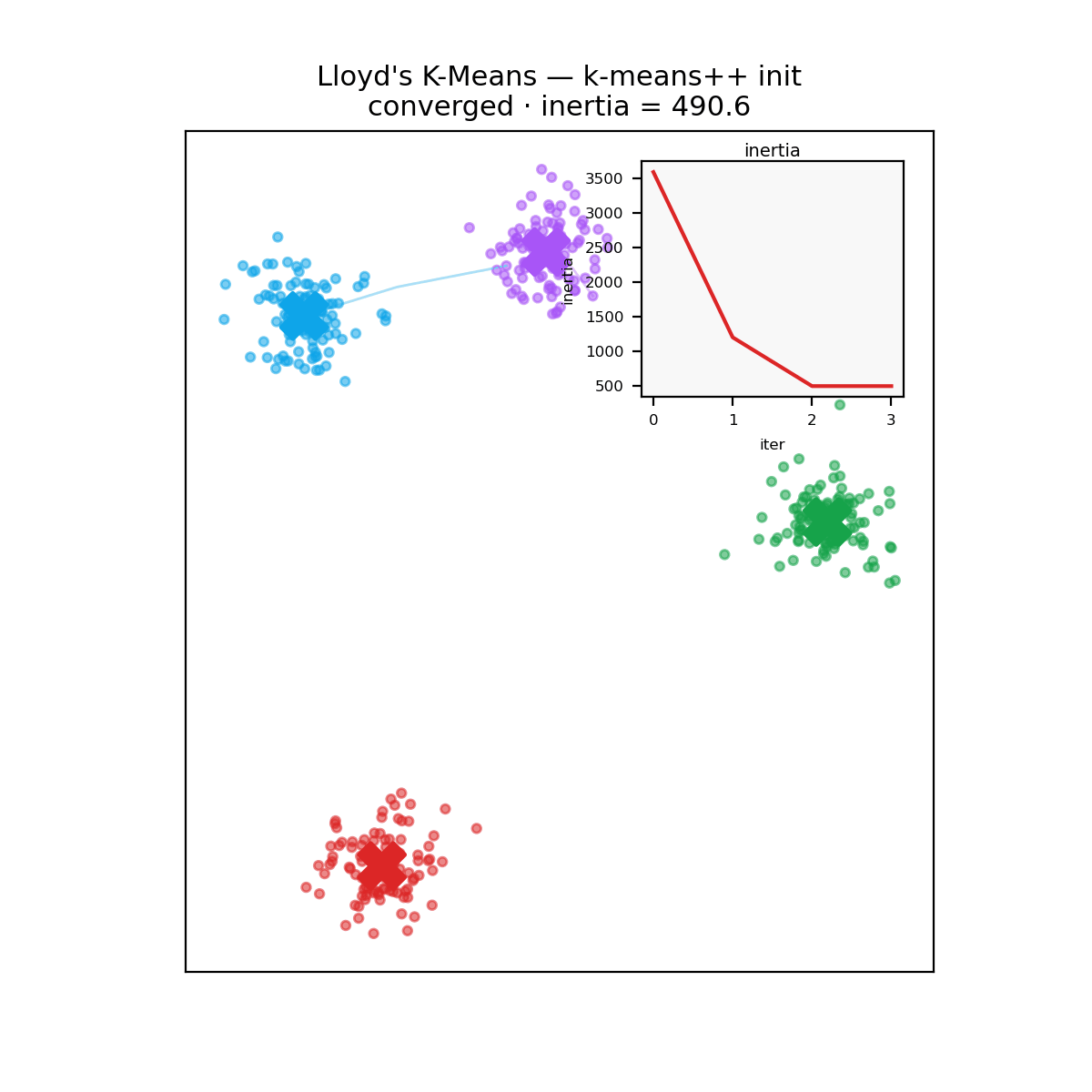
What no rewrite fixes
A reminder before the verdict: k-means carves space into convex Voronoi cells around its centroids, so it assumes roughly round, similarly sized clusters. Hand it two concentric rings and every implementation, in every language, fails identically.
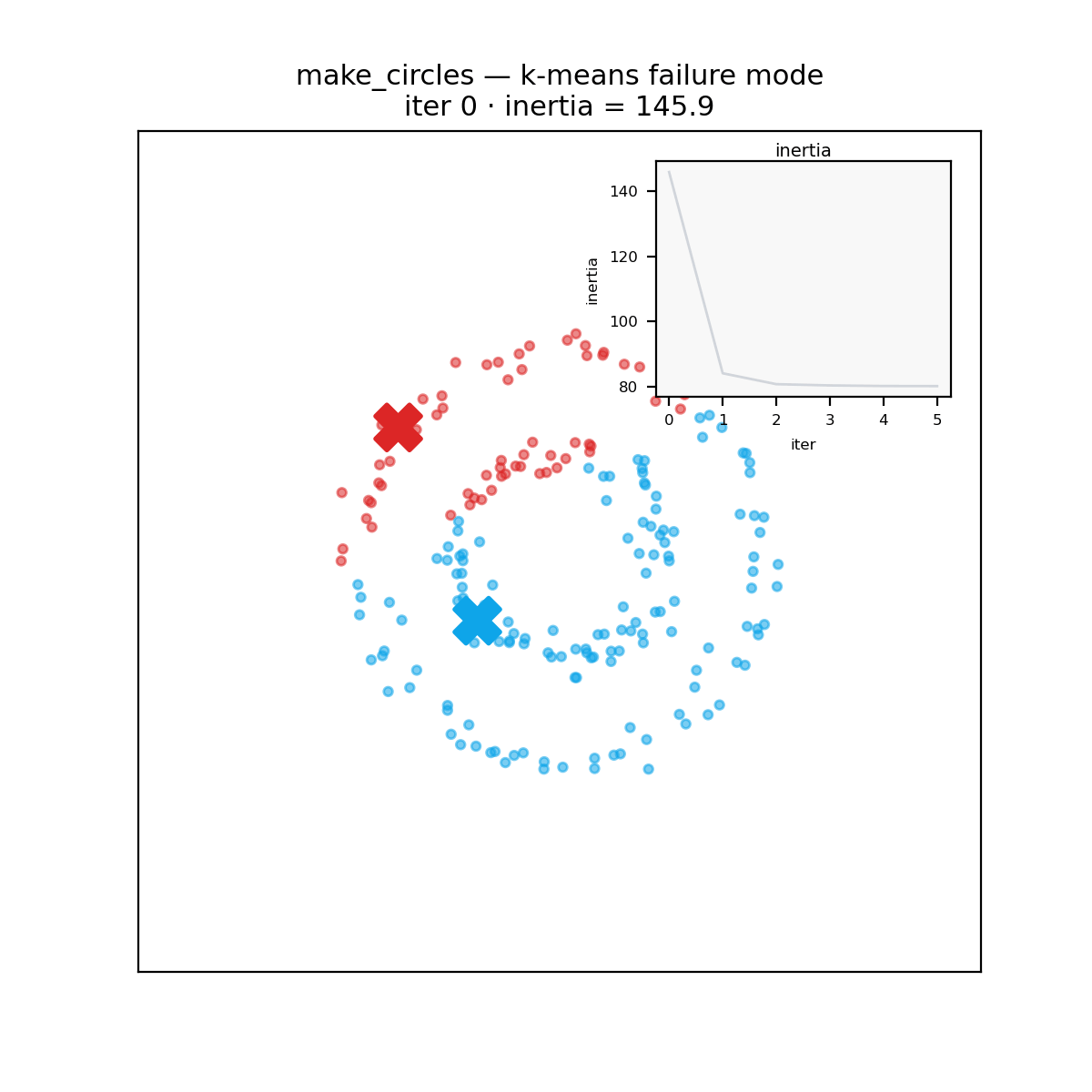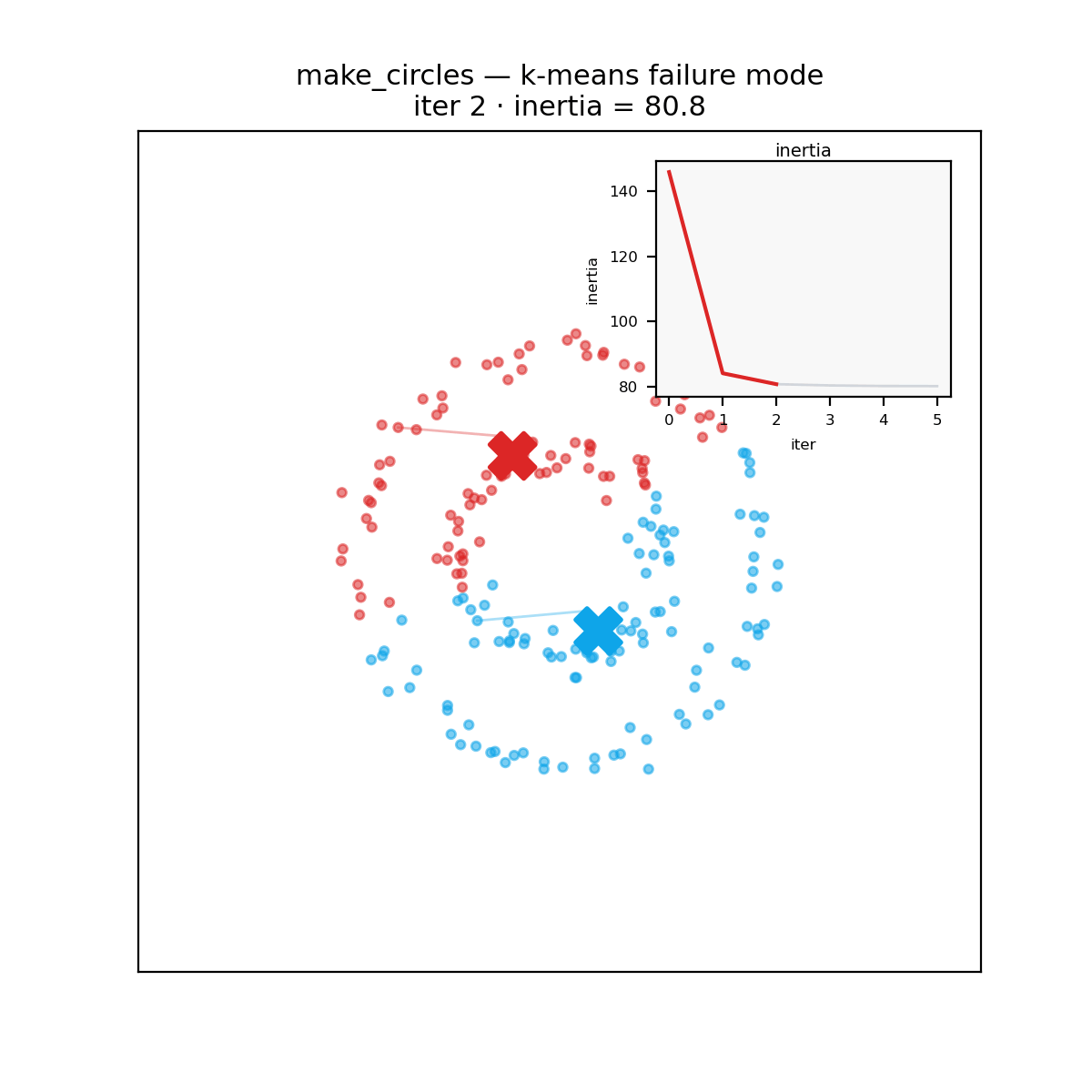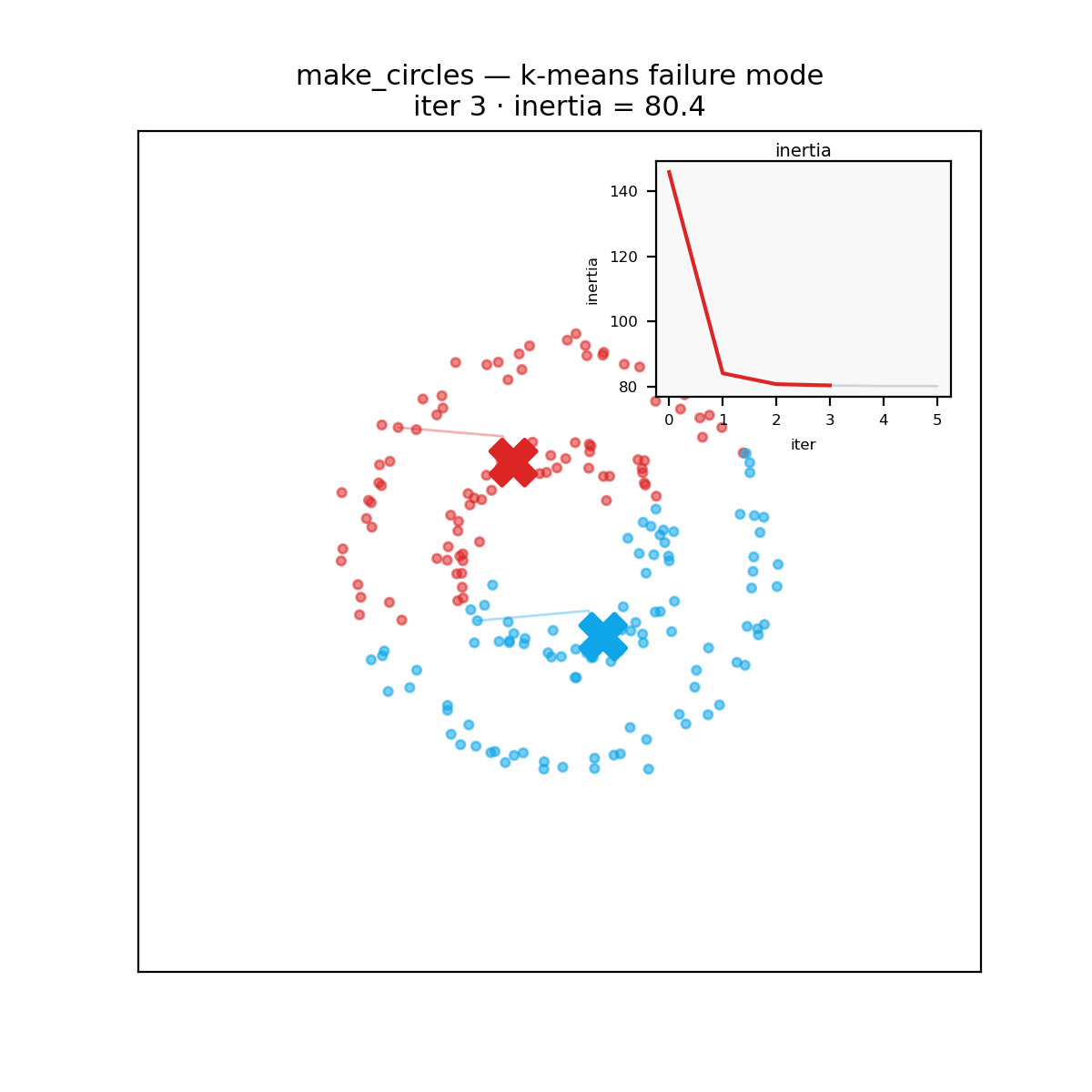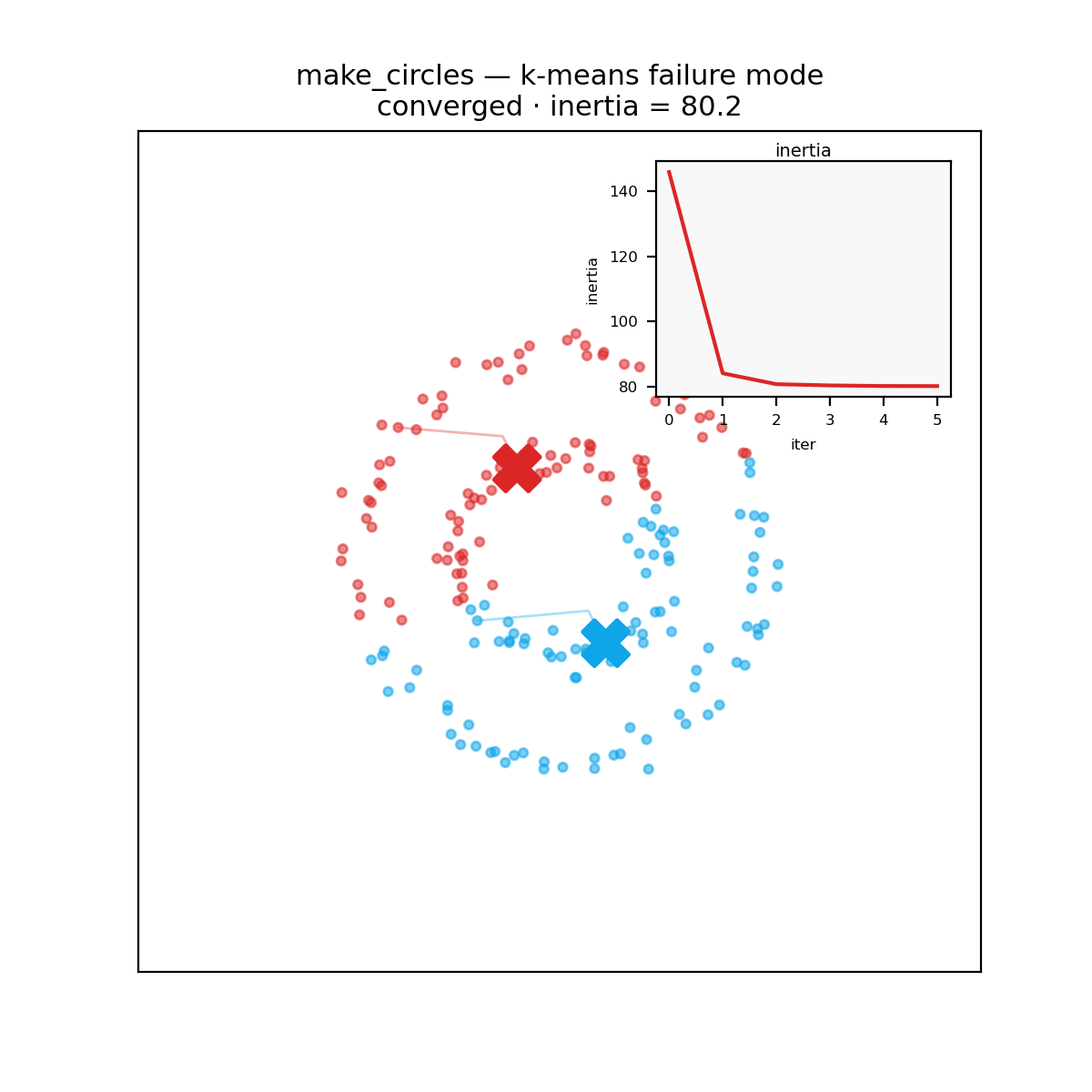
The verdict
If your bottleneck is a NumPy k-means at small or medium n, the reflex is vindicated: hand-rolled Rust runs about 4.5x faster at the median, uses an order of magnitude less memory, and the memory advantage doesn’t erode as the data grows. Push to large n and large k and tuned linear algebra takes over; rewrite to beat your interpreter, not BLAS, and if you need that corner too, the answer is a flat-matrix, GEMM-backed Rust rather than more threads. Threads were the smallest lever in the whole project, and the biggest one was free: matching the initialization closed the accuracy gap entirely and cut inertia by up to half.
| Situation | Reach for |
|---|---|
| Small/medium NumPy k-means bottleneck | Hand-rolled serial Rust: ~4.5x faster, ~11x leaner |
| Very large n × k | scikit-learn, or a BLAS-backed flat-matrix Rust |
| Accuracy matters most | k-means++ on any engine; it closed the gap for free |
| Memory is the constraint | Rust, at every size |
| Hoping threads will rescue it | Measure granularity first; Rayon bought 1.3x here and hurt at small n |
The honest caveats: one machine (M4 Max), sampled RSS rather than kernel-max, heavy-tailed runtimes (trust the medians), and a Rust implementation whose data layout leaves performance unclaimed. Within those bounds the answer to “just rewrite it in Rust?” is: yes at the small end, where the reflex started; no in the big-GEMM corner; and either way, fix your init first.
Run the live WASM demo Browse the code
All three implementations, the sweep harness, and the full Plotly dashboards are in the repo; the project page has the shorter summary. Clone it and watch where the crossover lands on your own hardware. The exponents above belong to my CPU’s cache hierarchy and BLAS build as much as to the algorithm.