
Every digit in the banner above started as pure static. No digit was retrieved, copied, or stitched together from training images. A small neural network looked at random noise and, in ~50 steps, removed its way to a handwritten number. You can replicate the full exercise locally, the whole thing is about three hundred lines of PyTorch.
A diffusion model is a generative model that learns to reverse a gradual noising process. You take real data, destroy it by adding noise in small steps until nothing is left, and train a network to undo one step of that destruction. To generate something new, you hand the network pure noise and let it walk the destruction backwards. That is the entire idea, and it now produces the best image generation that the field has managed till now!
Three weeks ago OpenAI showed DALL·E 2, where you write a caption like “Picard riding on Voyager, through Delta Quadrant’s unique planets” and the model “paints” it. Underneath the headline results sits the same denoising process loop I am about to build using MNIST. So this post has two parts :
- First I build a denoising diffusion model from scratch and watch it hallucinate digits and clothing
- Then I walk the short, fast ladder of papers, all published between 2020 and last month, that carried this idea from “interesting on CIFAR” to DALL·E 2.
The companion code is at ddpm-from-scratch. Every figure below comes out of it.
The whole idea in one picture
There are two processes - One is deterministic noise addition and the other one is learned denoising.
The forward process takes a clean image and adds a small amount of Gaussian noise, then adds a little more, and a little more, for $T$ steps, until the image is indistinguishable from static. This process has nothing to learn. It is a deterministic recipe with a fixed schedule of how much noise to add at each step, chosen before training started.
The reverse process is a neural network. It learns to look at a noisy image and undo one step of the forward process, nudging it back toward something slightly cleaner. Stack a thousand of these nudges and we walk all the way from static back to a plausible image.
The trick that makes this trainable with relatively small compute is that we don’t have to run the forward process step-by-step during training. Since each step adds Gaussian noise, and Gaussians stack into Gaussians, we can jump straight to the noise level at any step t in one shot.
Step 1: destroy an image by design
Let the noise schedule be a sequence of small numbers $\beta_1, \dots, \beta_T$ (I used $T = 1000$). Define $\alpha_t = 1 - \beta_t$, and let $\bar{\alpha}_t$ be the running product of every $\alpha$ up to step t:
Then the noised image at step t, given the clean image $x_0$, has a closed form:
Visualize it as a slider, i.e. $\bar{\alpha}_t$ starts near 1 and decays toward 0 as t grows, so early on you keep most of the image and add a whisper of noise, and late on you keep almost none of the image and it is nearly all noise. There is no network in this equation. It is arithmetic, and it is the whole forward process. In code it is two lines:
def q_sample(self, x0, t, noise):
# jump straight to the noise level at step t ( reparameterization )
A = extract(self.sqrt_alphas_cumprod, t, x0.shape) * x0
B = extract(self.sqrt_one_minus_alphas_cumprod, t, x0.shape) * noise
return ( A + B )
Here is a real 3 from MNIST run through q_sample at increasing t. Watch it dissolve step by step, as we add more noise.

That schedule deserves a second look, because the first thing the field improved after the original model was exactly this curve. The original DDPM paper used a linear schedule, where $\beta_t$ grows linearly. A year later, Improved DDPM pointed out that on small images the linear schedule destroys the picture too fast, so the last few hundred steps are nearly pure noise and teach the network almost nothing. Their cosine schedule keeps signal around for longer. I use the cosine schedule, and you can see why below.

Step 2: train a network to undo one step
Now the only learned part. We want a network that, given a noisy image $x_t$ and the step t, removes noise. There is a choice to make about what exactly it should output, the clean image or the noise that was added, and DDPM picks the noise. The network $\epsilon_\theta(x_t, t)$ guesses the $\epsilon$ that was added, and the loss is just the mean squared error between the true noise and the guess.
This drops out of a variational bound on the data likelihood, with a few weighting terms thrown away because the simplified version trains better. I am skipping that derivation on purpose; it is in the DDPM paper if you want it, and the practical loss is what matters here. The training step is short:
def p_losses(self, model, x0, t):
noise = torch.randn_like(x0) # the target
x_t = self.q_sample(x0, t, noise) # noise the image to level t
predicted = model(x_t, t) # ask the network to guess the noise
return F.mse_loss(predicted, noise) # how wrong was it
The full training loop is the loop you already know from any supervised model, with one extra line that picks a random noise level per image:
for x0, _ in dataloader:
t = torch.randint(0, T, (x0.size(0),)) # a different noise level per image
loss = diffusion.p_losses(model, x0, t)
opt.zero_grad(); loss.backward(); opt.step()
ema.update(model) # keep a moving average of the weights
The ema.update line earns its keep. Sampling from an exponential moving average of the weights rather than the live weights noticeably cleans up the samples in my runs, and it costs nothing but a copy of the parameters.
What about the network itself?
It is a U-Net, the same encoder-decoder-with-skip-connections shape used everywhere in image-to-image projects, with one diffusion-specific addition: the step t is turned into a sinusoidal embedding and injected into every block, so the same weights can behave differently at high noise and low noise. The multi-scale shape is deliberate: denoising is at once a global-structure and a local-texture job, and the skip connections let the network settle the broad shape in the bottleneck while carrying fine detail straight across, the coarse-to-fine behavior the sampling figures will show. Mine is about 10M parameters, small by any standard. We’re not going to walk through U-Net line by line; check it out in unet.py
Trained on MNIST for forty epochs, the loss falls fast and then crawls. The crawl is fine; diffusion loss values are a poor proxy for sample quality, and the samples keep improving long after the number stops moving.

Step 3: sample by denoising pure noise
Training taught the network to undo one step. Sampling chains it. Start from pure Gaussian noise $x_T$, ask the network for the noise, form a slightly cleaner mean by subtracting it, add back fresh randomness scaled by the step’s variance, and step down to $x_{t-1}$. (That variance is fixed by the schedule here; Improved DDPM later made it learnable, which is the log_var term in the code below.) That last bit of randomness is what keeps each run different; drop it and the reverse process turns deterministic, which is exactly the trick DDIM turns into a feature later. The reverse step in code, where the subtraction lives inside p_mean_variance:
@torch.no_grad()
def p_sample(self, model, x_t, t):
mean, log_var, _ = self.p_mean_variance(model, x_t, t) # uses eps_theta
noise = torch.randn_like(x_t)
nonzero = (t != 0).float().reshape(-1, 1, 1, 1) # no noise on the last step
return mean + nonzero * (0.5 * log_var).exp() * noise
Run that from t = 999 down to t = 0 and an image condenses out of the static. This is the figure that made diffusion click for me: a single sample, photographed every hundred steps as it resolves from noise into a digit.

Do this for sixty-four independent noise samples and you get a sheet of digits, none of which exist in MNIST.

Retraining on clothes
A fair worry at this point is that MNIST is a pushover and the model memorized ten shapes. So I changed one command-line flag, --dataset fashion, retrained the identical architecture on Fashion-MNIST, and changed nothing else. Same schedule, same loss, same sampler.


Making it usable: DDIM and fewer steps
There is a catch I have been quiet about. Sampling ran the network a thousand times for a single image. That is fine for a blog post and ruinous once you need more than a handful of images. The first fix arrived almost immediately, in DDIM (Song, Meng, and Ermon, late 2020).
DDIM reuses the exact same trained weights, with no retraining. It reinterprets the reverse process so that the steps are no longer required to be a Markov chain, which lets you skip most of them and, in its deterministic ($\eta = 0$) setting, makes the same starting noise always map to the same image. The per-step logic is “guess the clean image, then jump partway back toward it” (schematic):
x0 = predict_clean_image(img, t, eps) # invert the forward equation
img = sqrt(abar_prev) * x0 + sqrt(1 - abar_prev) * eps # re-noise to an earlier step
The practical payoff: I can sample in 50 steps instead of 1000, a 20x speedup, with barely any loss in quality. Below, the same network sampled with 10, 50, and 1000 steps.

This is the part of the from-scratch model that points straight at the rest of the field. Once sampling is cheap and the objective is this stable, the obvious next questions are: can we make the samples sharper, can we steer what gets generated, and can we afford to do it at megapixel resolution.
One note before the papers, because the model I built has a gap the next section leans on. It draws a digit, never the digit you ask for, because it never saw a label. Conditioning fixes that with a small change: you hand the network a class label alongside the timestep, as one more embedding added in exactly like t, and train it to denoise with the label in view. Every kind of steering below is built on that one hook, so I added it to my MNIST model and trained the conditional version, which the guidance section puts to work.
How this became DALL·E 2
Everything above is the 2020 core: DDPM plus DDIM. What turned it into the system that drew the astronaut on the horse is a short ladder of papers, each fixing one specific limitation. Here is that ladder, in order.
Sampling speed: DDIM (2020). Covered above. The line to remember: a thousand steps became fifty, which is what made everything downstream practical to iterate on.
Sharper samples and a better schedule: Improved DDPM (2021). Nichol and Dhariwal contributed the cosine schedule I used, plus the idea of letting the network learn the reverse-step variance instead of fixing it. They reported better log-likelihood and fewer sampling steps. The schedule alone is the kind of change that costs one function and improves everything after it.
The unification: score-based models and SDEs. Running alongside diffusion was a second line of work, score matching (Song and Ermon, 2019), which learns the gradient of the data density and samples by following it. In late 2020, Song and colleagues showed that diffusion models and score-based models are the same object written two ways: predicting the noise is, up to a time-dependent scaling, estimating that gradient at each noise level, and both are discretizations of one continuous-time stochastic differential equation. Worth knowing, because the literature switches between “diffusion” and “score-based” language as if you should already know they are the same.
Beating GANs: classifier guidance (May 2021). Dhariwal and Nichol tuned the architecture and added classifier guidance: at sampling time, nudge each step with the gradient of a classifier trained on noised images toward the class you want. The result beat the best GANs on ImageNet, which is the moment the field’s default flipped from GANs to diffusion. The catch in the title is real but conditional: this was one benchmark, ImageNet, with one carefully tuned setup. What guidance actually buys is a knob that trades sample diversity for fidelity, by sharpening the conditional distribution.
Dropping the classifier: classifier-free guidance (Dec 2021). Training a separate classifier on noisy images is awkward, and it pins you to a fixed set of labels, which is useless for free-form text. Ho and Salimans (NeurIPS 2021 workshop) removed it. Train one network that sometimes sees the condition and sometimes sees a blank, then at sampling time extrapolate between the two predictions:
\[\tilde{\epsilon}(x_t, c) = (1 + w)\, \epsilon_\theta(x_t, c) - w\, \epsilon_\theta(x_t, \varnothing)\]Here $c$ is the condition (a class, a caption), $\varnothing$ is the blank, and $w$ turns the steering up. Most implementations write the same thing with a guidance scale $s = 1 + w$, where $w = 0$ (so $s = 1$) means no steering, so if you compare two codebases and the numbers look off by one, that is why. Classifier-free guidance is the workhorse of every strong text-to-image model that followed.
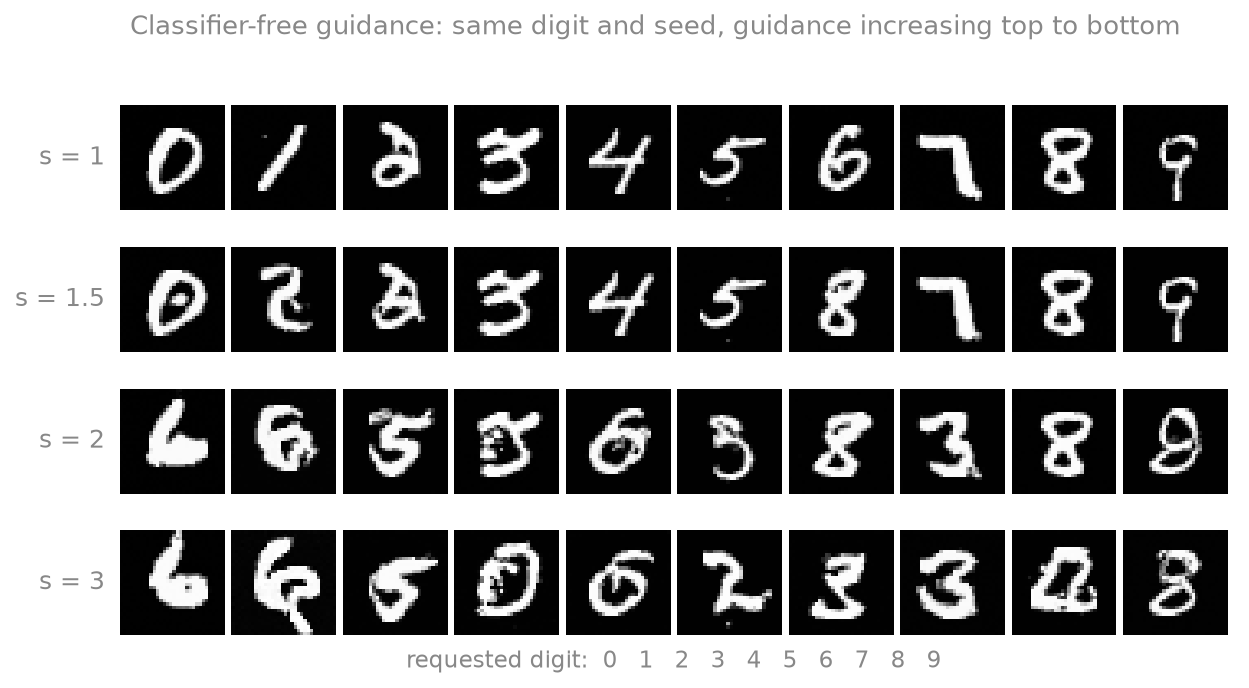
This is the one rung I can run myself. Classifier-free guidance needs a model that can sample both with and without the label, so I trained exactly that on MNIST: a conditional U-Net with the label dropped 15% of the time. First the basic question, does the label even steer it? Same ten starting seeds, run once ignoring the label and once told which digit to draw:

Now turn the guidance dial up. More guidance trades diversity for fidelity, sharpening each sample toward its class. On a model this small, the usable range is narrow:
Affording resolution: latent diffusion (Dec 2021). Diffusing directly on megapixel pixels is brutally expensive, because the U-Net runs at full resolution a thousand times. Rombach and colleagues moved the diffusion into the compact latent space of a pretrained autoencoder, cutting the cost by roughly an order of magnitude while keeping quality, and wired in cross-attention so you can condition on text or layout. This is the architecture that, later in 2022, would become Stable Diffusion, though as I write this that release does not exist yet.
Text-to-image: GLIDE and DALL·E 2 (Dec 2021 to Apr 2022). GLIDE was the first strong text-to-image diffusion model and showed classifier-free guidance beats CLIP-based guidance for following captions. Then DALL·E 2, three weeks ago, restructured the problem around CLIP, a model trained to match images with their captions: a prior turns the caption into a CLIP image embedding, then a diffusion decoder turns that embedding into a picture, with classifier-free guidance doing the steering. The authors call it unCLIP, and they find a diffusion prior works better than an autoregressive one, so there is diffusion on both ends. Note that this is a different lineage from latent diffusion; DALL·E 2 is not a latent-diffusion model, even though both are text-to-image systems and it is easy to blur them together.
What is still hard
A few things that were still genuinely unsolved, from where I sat in May 2022.
Sampling is still slow next to a GAN, which generates in a single forward pass. DDIM helped a lot, fifty steps instead of a thousand, but that is still fifty forward passes to the GAN’s one, and the race to cut that further has already started: progressive distillation, out this February, halves the step count and then halves it again. Evaluation is shaky too. FID (Fréchet Inception Distance) is the standard number and it is a blunt instrument, and “does this image match the caption” has no clean metric at all.
The compute needed is a core gap - impressive results come from models far larger than anything that can be trained locally, and what separates “can build this on MNIST” from “can build DALL·E 2” is mostly scale & data available.
Guidance carries the cost the figure above showed in miniature: the lower rows thicken, oversaturate, and slide off the manifold of real images.
Build it yourself
The model in this post is small enough to read in one sitting and train on a laptop, which was the whole point. If you want the denoising idea to stop being abstract, clone the repo, run train.py, and watch the sample grid fill in epoch by epoch. The forward process, the loss, and both samplers are each a handful of lines, exactly as shown above.
Browse the code Read the DALL·E 2 paper More deep learning from scratch